After an initial introduction to The Computer's Generative Cut class I should/want to think about how EXACTLY I want to proceed and what to learn, how to use it and what to ask Max for.
> Using Subtitles > Not applicable if I want to use my self - shot footage
> Using Sound > Also not applicable with self-shot footage for which sound will be composed in post-production
> Using Image analysis > ??? > (camera) movement > If /When making the effort it should have a MEANING , Ideally the computer's cut reveals something about the work that might of stayed hidden otherwise
Perhaps it makes more 'sense' to include a second part of the video of found footage which is then a supercut and to blend the two ( found footage edit + self shot) ? BUT A SUPERCUT OF WHAT ? > Something topic related
I find it rather likely that I will opt for adding a 'supercut' edit based on metadata -
> maybe I can edit specific video, like of a certain genre of footage and edit it based on an animalistic perception parameter
> or it will be on onslaught of found footage ( like video essay style) to illuminate also the 'man made world ' into the data set
> maybe I can have a multichannel set up in which the one screen represents one data set (e.g. nature) - the other another (e.g. youtube found footage, human archive) and a third the machine learned/computer vision synthesis and they are played in part parallel but primarily succession of one another?


1 Subtitles
2 Sound
3 Image
What kind of computer based (editing) structure would make sense for the work?
Generative sound?
Concrete outline: which computer process would make sense? What programs and steps would be necessary?
Generative editing?
Can I possible edit the image recognition scripts
and have it say ' if something is detected then cut' (Instead of drawing the red rectangle as in the examples?
Or could I use the Python code setup ( pertained neural net ) and use instead of
protopath = "MobileNetSSD_deploy.prototxt"
modelpath = "MobileNetSSD_deploy.caffemodel"
detector = cv2.dnn.readNetFromCaffe(prototxt=protopath, caffeModel=modelpath)
different sets to 'decide' from and a different detector?
Because the way it is used here we are not defining the parameters for detection of the CLASSES - we are only using/ calling upon a certain path
What kind of footage would the 3rd party/found footage be?
For me it's not about THE SELECTION BUT THE COMBINATION.
I don't want to not have control over which clips will be in the video but I want to PASS AUTHORITY/POWER/DECISION OVER WHEN WHICH CLIPS IS PLAYED and in which ORDER.
So I would like a set up, where I have a set of video files and based on a given principle the Algorithm/ Code/ Computer selects what is visible, when, in which order.
So not the clip itself but the order/combination / 'the edit'
So the computer is not 'viewing' and cutting ( the raw footage ) but is 'viewing' and making the 'next decision' (next clip)
> Hereby I am not making a 'super cut' and learning something from the computers edit but I am outlining the process of the machine learning from (to evaluate and deal with) the data/footage


Image recognition / category / class / thing > leads to cut
Is very difficult because the footage I will be working with has very hard to recognise content
Also I realise I don't want the code to cut for me I want it do edit together.
Subtitles are possible when using 3rd party /Found footage > WORD/MEANING analysis of 3rd party content
I could give the 'suggested AI inside the video' the found footage as an 'ever increasing/expanding database of the internet'. Hereby, teaching the AI meaning/content through WORDS.
Difficulty here is that the type of found footage I am interested in is NOT (so) WORD BASED.
Pure Data sound detection > used in our case as note extraction to play another musical file/ other MIDI file is not applicable to my context.
Moreover, the sound in found footage would in my use case be so arbitrary that it would serve no added value. ( + the work is about VISION at it's core)
Therefore, I did not finish this assignment as I am being selective as to what is useful for my MA Thesis and dropping the rest.
Sound generated based on what is 'seen' by the computer; Imaginable that the sound of the final video is responsive to the visual; there could be a set of sounds and based on the OBJECT RECOGNITION OR COLOUR a certain sound would appear. Basically the 'fictive AI' would be still in a primitive/early level 'just' recognising colour but learning VISION AND RECOGNITION.
If python script can be used for object or colour recognition this would: (1) elevate video to audiovisuelle algorithmic artwork, deploying machine learning processes onto itself. (2) suggest the narrative of a learning AI, taught to SEE/ Computer Vision through offered Dataset of sound footage. The two types of visuals material would be to be understood as 1) 'THE GENERATOR' ( SELF PRODUCED FOOTAGE) vs. 'THE DISCRIMINATOR' ( 3RD PARTY/FOUND FOOTAGE / ei. Dataset)
> Could it be possible to set up a dialogue between these two types of footage? e.g. 'If recognises this ... Then cut to ..?
Live Editing of the footage based on an algorithmic principle?
Recognising colour ( saturation/hue) is probably most do-able/ applicable to the types of video I will be using and producing.
> Colour recognition > vision > computer vision > leads to sound
( * a sign of the machine learning > a 'learning response' )
This way I could keep full control over the visual, while having added
the 'computer vision' onto it. > 'Generative sound design'
The machine vision - running a code for object detection - REVEALS something about the machine learning. It lets the viewer wonder ' What is the machine seeing?' 'What has it learned?' 'How is it differently trained than a human?' 'How do I see?' 'How do I detect categories through vision and recognition?' ' How are humans and machines different?'
> The asking of such questions is something I would enjoy to in my MA work.
> Asking of questions inspired in the viewer. Not just me dealing with it in the work.
How much in the original video can be put back together with image recognition of this script? Will the original course of events come through?
Or do an iconic film bicycle supercut compilation.
What could I make the machine SEE ABOUT nature..?
Can use other neural net, to be found online - possibly one specialised to a certain category ( 'caffemodel is most common used' )
or even train own neural net by e.g. having 3 thousand images of turtles etc.
> like cross lucid did with their data scientists, build from ground up > but in my use case I don't need the data collection to be self-made because it is about tapping into a general - more global knowledge or cognition level.
And in my own footage I would never a mass enough of one category to make the machine learn anything. Therefore not useful.
In the future it might be interesting to see if a machine can learn one artists style and generate (GAN style) art within this artists oevre from that info..
Python beginner tutorial: https://www.youtube.com/watch?v=_uQrJ0TkZlc
Maybe it does turn into a multichannel situation; where the one part of the installation is 3rd party footage, editing selection/order made by a computer ( but what value does this add?)
While the main video is the GAN generating and producing 'real world nature footage' made from the 'eyes of' the animals it is learning about/to see like.
(+ Additional occasional injections of the humanoid forming AI presence)
Maybe I can really move beyond the desktop viewing mode and think more along the lines of a multichannel video installation .
At the same time I want it to stay online shareable but I think it can be both..
How can the video become alive?
How can machine learning be present and shape the video in a 'smart' way?
https://www.youtube.com/watch?v=oJ5dQ_Pdfac
https://www.youtube.com/watch?v=kBFJ7HtbizA
https://www.youtube.com/watch?v=kBFJ7HtbizA
https://www.youtube.com/watch?v=Q8iDcLTD9wQ
Amazonian Giant Water Lily
https://www.youtube.com/watch?v=WPR8kxTyG9Q
Amazing! Giant waterlillies in the Amazon - The Private Life of Plants - David Attenborough - BBC wildlife - https://www.youtube.com/watch?v=igkjcuw_n_U
Could ask the computer vision what is sees?
where it sees similarities?
True Facts: Freaky Nudibranchs
https://www.youtube.com/watch?v=F7V8DRfZBQI
What we are doing right now is to have object recognition of a object in video and then to get the IN and OUT point to use this as editing information. We want to use it to make a cut - but could also use this info of IN and OUT of when something is IN FRAME to
(1) e.g. activate a sound reaction?
(2) or could I give the command that after a certain colour is recognised the computer moves to the next colour in a colourwheel/coloursheme > hereby the editing-ORDER is based on if a certain COLOR is RECOGNISED and this determines the edited SEQUENCE of the video.
But I AM interested to see what happens if I replace the prer- trained neural net ( e.g. instead of
protopath = "MobileNetSSD_deploy.prototxt"
modelpath = "MobileNetSSD_deploy.caffemodel"
detector = cv2.dnn.readNetFromCaffe(prototxt=protopath, caffeModel=modelpath)
I would use another network that has a CLASS for 'Nature' and see if the network can recognise abstract nature or not.
"Image classification has been further accelerated by the advent of Transfer Learning. To put it simply, Transfer learning allows us to use a pre-existing model, trained on a huge dataset, for our own tasks. Consequently reducing the cost of training new deep learning models and since the datasets have been vetted, we can be assured of the quality.
In Image Classification, there are some very popular datasets that are used across research, industry, and hackathons. The following are some of the prominent ones:
ImageNet
CIFAR
MNIST
and many more. " - https://www.analyticsvidhya.com/blog/2020/08/top-4-pre-trained-models-for-image-classification-with-python-code/
"The objective is clear: Get the in and out points from Objects appearing and disappearing in the video into a Shotcut XML list."
Hereby the final video would be edited/organised by colour as recognised by the computer vision. (Because the footage I choose is so abstract it would be hard to apply any other category to it.)
Like a toddler of 18months in a specific learning phase/ early development for colours.
How does the machine look at the image? as a total? pixel by pixel?
How does 'recognition' to a machine?
Rather: What can the application of a pre-trained neural networks idea of nature tell me about the computers vision ( and 'understanding of') NATURE
Source material
If machine learning is the act of pattern recognition - this stands in some relation to "the development of life as for the emergence of shapes and patterns."
The quality of the footage could also more clearly identify that this is 3rd Party material
Mating Leopard Slugs - https://www.youtube.com/watch?v=bxE-gZzo9HA
Spiral - https://www.youtube.com/watch?v=feKYw5Adheg&ab_channel=NatGeoWILD
Extended version - https://www.youtube.com/watch?v=wG9qpZ89qzc&ab_channel=unireality
Amazing Fish Form Giant Ball to Scare Predators | Blue Planet | BBC Earth https://www.youtube.com/watch?v=15B8qN9dre4&ab_channel=BBCEarth
Indeed these kinds of shapes, patterns, textures are what GAN /neural networks learn to see our world on ( my abstraction of that is just the artistic touch/artistic abstraction) but the simulated process of a DATA-TRAINING SET is equivalent to reality.
And these same forms and textures become visible in the GAN.
My video-artwork creates analogies there.
Puffer Fish Creates This Blue Water Art
https://www.youtube.com/watch?v=B91tozyQs9M&ab_channel=crestedduck64
Watch Fish Reproduce....Caught on Camera!! - https://www.youtube.com/watch?v=qnPJ3_0ZQRA&ab_channel=AdamC
And slowly I too feel like a database looking through and selecting all this footage on specific parameters...
If These 15 Creatures Were Not Filmed, No One Would Believe It
https://www.youtube.com/watch?v=-8HeX5xFxYM&ab_channel=TheSweetSpot
If These 15 Creatures Were Not Filmed, No One Would Believe It
https://www.youtube.com/watch?v=-8HeX5xFxYM&ab_channel=TheSweetSpot
QUESTION: Do I want to ad 'domestic vide0 footage' to give it that 'youtube quality'
because I also want to make sure not to have this National Geographic style video
This is an example of using the MobileNet pre-trained neural network, which give me the idea that yes I could run the footage I select past a neural net architecture and ask it what it recognises.
GIVE A GLIMPSE INTO WHAT THE MASCHINE SEES.
It would nontheless be more elegant to have this evoke something in the visual editing and not have it as this add on test print out.
Stag Beetle Throws Girlfriend Out Of Tree | Life | BBC Earth https://www.youtube.com/watch?v=XI8WU9ReFG0&ab_channel=BBCEarth
Prüfung anmelden - ja - nein?
The thing is I didn't do anything or contribute anything that would deem something 'proof-able'. I would have to most probably still create some 'Abgabe' until the end of semester and neither do I have the ambition nor the time to do this. This class was always about figuring out how it can be useful to my MA thesis and not about creating an additional 'Prüfungsleistung'. So no, I will not register for grading, because there is nothing to grade.
Black out everything that isn't the detected target?
Or use further source material to emphasise/clarify what is being detected from the same video in sections?
how much of the story do you still get from the machine vision ?
BABY CHAMELEON Changes Color Pattern (1 DAY OLD)
https://www.youtube.com/watch?v=6WbLtN6FMmc&ab_channel=TheAnimalBoxOffice
GANs are a form of machine learning
GANS use neural networks
neural networks as well are modelled on human brains
"Artificial neural networks (ANNs), usually simply called neural networks (NNs), are computing systems inspired by the biological neural networks that constitute animal brains.
An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron receives a signal then processes it and can signal neurons connected to it. The "signal" at a connection is a real number, and the output of each neuron is computed by some non-linear function of the sum of its inputs. The connections are called edges. Neurons and edges typically have a weight that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection. Neurons may have a threshold such that a signal is sent only if the aggregate signal crosses that threshold. Typically, neurons are aggregated into layers. Different layers may perform different transformations on their inputs. Signals travel from the first layer (the input layer), to the last layer (the output layer), possibly after traversing the layers multiple times."
My creative/artistic work is about these new machine learning technologies because THESE are the topics of our times. This is the future, this is what is happening, this is the frontier, here new things will be explored and developed. These are - if you will - the conflicts of our times. Here there is something to be learned, that goes beyond me and can be applied beyond me.
source: https://pub.towardsai.net/main-types-of-neural-networks-and-its-applications-tutorial-734480d7ec8e
Is machine learning not algorithmic?
What is an AI Framework?
"An AI framework is a programming framework that enables you to create AI models (models can be part of applications) without writing everything from scratch. Two examples of such AI frameworks include TensorFlow and PyTorch. TensorFlow, which is created by Google, is the dominant player right now in the commercial space, and researchers tend to love PyTorch (created by Facebook). I use TensorFlow, with its Keras API, and it allows me to create AI models very fast."
Glowworms in Motion - A Time-lapse of NZ's Glowworm Caves in 4K
https://www.youtube.com/watch?v=JC41M7RPSec&ab_channel=StokedforSaturday
These Carnivorous Worms Catch Bugs by Mimicking the Night Sky | Deep Look
https://www.youtube.com/watch?v=vLb0iuTVzW0&ab_channel=DeepLook
Further approach possibilities creating a (more) generative videowork
/ approaching it like a media artist in 'Gestaltung medialer Umgebung' and not only a director who storyboards every frame out
try to understand the machines pictorial understanding > computer vision
using Pix2Pix process to teach neural network with own visual inputs teaching neural network a specific style and letting it create actual output from this, not suggesting /simulating a dataset but using my image selection as dataset ..
* the thing is at this point I'm still very open what the machine learning should be or can be or which network to use in which way, because my approach comes from the visual direction and I think it's fine to be open about wanting to use some form of machine learning on the material, but not knowing yet which this is .. what bothers me is that I was quite far and now the ML part is starting to become so big that it's taking over the Expose but I can't be specific about this because I don't have enough research. So I can't be so straight cut and say ' I want to use ML to do this' because that's not what it's about , rather it's about using ML processes as an artistic tool; maybe the aim is to step into a dialogue with the machine and see what it 'understands' and produces from the input I give. Maybe to make the 'training process', the data input/data selection a focal point and enter into a creative dialogue with the machine..?
What if I let go of the 3rd party footage ( or let it flow into a learning of the machine) but then have it apply that to the footage I create? going back to the question 'what would it look like if machines would learn to see the world not only through our eyes but through those of animals, which is of course only speculative because the footage I produce will also be MY interpretation..
10 INCREDIBLE Animals & Their Abilities https://www.youtube.com/watch?v=rMR3VYYpluo
Top 5 Animal Adaptations | BBC Earth https://www.youtube.com/watch?v=ZT8YswmQuAg
Model Zoo - other models to use for image recognition: https://github.com/BVLC/caffe/wiki/Model-Zoo
Pix2Pix Tutorial: https://medium.com/@jctestud/video-generation-with-pix2pix-aed5b1b69f57
The way to use these models is to create a really cool data set
building own dataset - what I want the machine to be "thinking" about
It sounds like I might not need such super high diversity in my data, if limited diversity in data leads to overfitting, which results in the outcome looking much like the input, in my case that's not such a big problem..
Playlist - most informative and useful videos:
Make ML Datasets: Week 1 (Introduction to models and dataset creation, dataset ethics)
https://www.youtube.com/watch?v=tYVeEssDWFM&list=PLWuCzxqIpJs-YLb2Yc3Y6rGJlYxVWFNoi
Use own videos and scraped videos as data input for StyleGAN by splitting into Frames using FFMPEG
However they need to be square and 1024 max pixel size in StyleGAN2 model training
> for my type of imagery this might just result in fuzzy, colour images
However, we still don't understand how these networks really learn because e.g. Tensorflow training set for flowers has some pretty bad images in it and it works well anyways..
Diffusion model using noise + initialised image + A TEXT PROMPT > to create imagery so I could create imagery from a poem..
https://colab.research.google.com/drive/1sHfRn5Y0YKYKi1k-ifUSBFRNJ8_1sa39
Dataset compilation
Site to scrub: 1: https://lygte-info.dk/review/Beamshot%20AAA%20lights%202011-07%20UK.html
Site to scrub: 2:https://lygte-info.dk/review/Beamshoot%20NiteCore%20EZAA%20comparison%20UK.html
Site to scrub: 3: Facebook : Team Trekkers Fous https://www.facebook.com/TrekkeurFous/photos/?ref=page_internal
Possible source material: Next Frame Prediction
Images taken: https://www.cavinguk.co.uk/holidays/NorthernWaterfalls2009/round3/
What I can already say from starting to compile files for a dataset is that the approach of machine learning is so based on repetition and pattern. In comparison to human learning based on experience; As a human I can go to the woods one time and fully experience that with all my senses in a kind of multidimensional way and then I have an understanding of what the forest, woods, trees, grass etc. is (to the point where I could create multiple datasets of imagery in my mind compiled from my memory.)
The machine on the other hand doesn't gain any 'understanding' it simply becomes good at the task it was tasked with.
The question does become how many good resolution? images do you need to train and get nice looking results that have something recognisable?
I wonder also why these networks are built on mass and not on quality?
Couldn't you teach a network on a few high quality images and train it on these 'in detail' through repetition? Do data scientists not do this because it wouldn't work or because they are aiming for a system that is open to diversity? Because this are not image creation tools in the first sense but rather surveillance tools.
StyleGAN is more about texture generation than shape so you want to reduce the amount of structural/shape changes and focus more on the textures you apply to it.
Predator Seaslug!!! https://www.youtube.com/watch?v=RYKim1OHSYA
Predatory Nudibranch - Melibe Viridis https://www.youtube.com/watch?v=RB6Wuw1SyrU
Tritonia diomedea bite strike - https://www.youtube.com/watch?v=g4u60Mv1Lu0
https://stackoverflow.com/questions/49419519/how-to-find-list-of-classes-objects-that-caffe-net-was-trained-with-and-also-th
BigGAN: Tensorflow Download: Google Colab link : BigGAN image generator trained on 128x128 ImageNet. https://tfhub.dev/deepmind/biggan-128/2
Large Scale GAN Training for High Fidelity Natural Image Synthesis - https://arxiv.org/abs/1809.11096
"Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale."
BigGAN Hubdemo https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/biggan_generation_with_tf_hub.ipynb
Developing a Dataset:
Bing gallery: saved imagery: https://www.bing.com/saves?&FORM=savim1&wlexpsignin=1
Alexander König: Recent Research&Projects: AInim - An Audio-Reactive AI-System trained with Hand-Drawn animation: http://www.media-art-theory.com/
A Gentle Introduction to StyleGAN the Style Generative Adversarial Network: https://machinelearningmastery.com/introduction-to-style-generative-adversarial-network-stylegan/
Google Doc Slides of this presentation with very helpful links: https://docs.google.com/presentation/d/18HsuaDWVWuk596xn_VxOzITVJRj-NiBdpjdJL8U4iVQ/edit#slide=id.g63d79feee6_0_799
A Style-Based Generator Architecture for Generative Adversarial Networks: https://arxiv.org/abs/1812.04948
Spreadsheet by Golan Levin on free Datasets online: https://docs.google.com/spreadsheets/d/1VijZSkQbqOvsvYBXdCx9UGu5zHGZPPpzwH2uHS-2XxQ/edit#gid=0
E.g. Caltec Birds 200: http://www.vision.caltech.edu/visipedia/CUB-200.html
SytleGAN - Tensorflow - Github: https://github.com/dvschultz/stylegan
Video-to-Video Synthesis: https://arxiv.org/abs/1808.06601
"We study the problem of video-to-video synthesis, whose goal is to learn a mapping function from an input source video (e.g., a sequence of semantic segmentation masks) to an output photorealistic video that precisely depicts the content of the source video. While its image counterpart, the image-to-image synthesis problem, is a popular topic, the video-to-video synthesis problem is less explored in the literature. Without understanding temporal dynamics, directly applying existing image synthesis approaches to an input video often results in temporally incoherent videos of low visual quality. In this paper, we propose a novel video-to-video synthesis approach under the generative adversarial learning framework. Through carefully-designed generator and discriminator architectures, coupled with a spatio-temporal adversarial objective, we achieve high-resolution, photorealistic, temporally coherent video results on a diverse set of input formats including segmentation masks, sketches, and poses. Experiments on multiple benchmarks show the advantage of our method compared to strong baselines. In particular, our model is capable of synthesizing 2K resolution videos of street scenes up to 30 seconds long, which significantly advances the state-of-the-art of video synthesis. Finally, we apply our approach to future video prediction, outperforming several state-of-the-art competing systems."
Image-to-Image Translation with Conditional Adversarial Networks: https://arxiv.org/abs/1611.07004
CycleGAN and Pix2Pix Github: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
How to use Dataset for StyleGAN
Relation between human brain and artificial neural networks ist mostly metaphorical and inspirational in a reductionist modelling of brain structures.
AI2050’s Hard Problems Working List
source: https://www.mouser.de/blog/deep-learning-entwicklung-neuronaler-netzwerke
Datasets
This beautiful video work is a documentation of the assembly of a rose pedal data set while also in INCREDIBLE example of how a film can be about the Topic of ML /AI without being stylistically or technically within that genre! Super inspiring for me to bring my OWN STYLE to this subject. & to gather the knowledge of these technologies but not be forced to apply them in the final work itself.
Artificial Neural Networks and animal intelligence
Thesis Literature AI
Articles and Research
Artworks Datasets:
https://datanutrition.org/labels/
https://carolinesinders.com/feminist-data-set/
https://annaridler.com/myriad-tulips
https://mimionuoha.com/the-library-of-missing-datasets-v-20
"there has been an explosion of research into the cognitive capacities of animals. Topics, such as episodic memory, theory of mind, and planning for the future were little investigated in 1985, whereas now they form the mainstay of animal cognition studies." https://www.frontiersin.org/articles/10.3389/fpsyg.2020.02072/full
To be considered : The term 'Intelligence' is not yet clearly defined. "“we should not become bogged down with a general intelligence concept for animals because its measurement is well beyond our grasp.” and the issue of measuring 'animal intelligence' across such varied perceptions and abilities.
animal cognition ; “the mechanisms by which animals acquire, process, store and act on information from the environment.”
https://maraoz.com/2020/07/12/brains-vs-anns/
"We can think of animal intelligence as a result of a nested optimization process of inner and outer loop learning. Innate behaviors and structure that facilitates lifetime learning are learned over a large evolutionary time scale (outer loop) through natural selection and other behaviors like salivating at the ringing of the bell are learned through the lifetime of an individual (inner loop). Outer loop learning encodes statistical regularities of the broader gene pool’s environment in the genome."
Neural networks are a series of algorithms that .. recognize relationships between vast amounts of data. They are used in a variety of applications in financial services, from forecasting and marketing research to fraud detection and risk assessment.
Ryvicker and Sena wrote that through advancements in convolutional neural networks, Netflix can detect and analyze underlying scene elements that drive viewer engagement. That data-driven approach, they wrote, can inform what content Netflix licenses and provide insight into production.
https://medium.com/analytics-vidhya/neural-network-how-it-works-and-its-industry-use-cases-30455d3fce11
Learning in machine learning = Weights and biases are learning parameters of machine learning models, they are modified for training the neural networks.
There are different use cases (also not image based at all) but essentially it all revolves aroundpattern recognition from large amounts of data.
https://www.analyticssteps.com/blogs/8-applications-neural-networks
this is especially interesting because here we have a sort of drone that looks at the air or underwater environment with a camera and uses CNN to process the camera image directly and make automated decisions without active human control. So an example of AI/ANNs being used at the front end of technology for image processing in setting much like my shooting environment.
"Convolutional layers form the basis of Convolutional Neural Networks. These layers use different filters for differentiating between images. Layers also have bigger filters that filter channels for image extraction. "
"Supervised Deep Learning and Machine Learning take data and results as an input during training to generate the rules or data patterns."

"Apply filters or feature detectors to the input image to generate the feature maps or the activation maps using the Relu activation function. Feature detectors or filters help identify different features present in an image like edges, vertical lines, horizontal lines, bends, etc.
Pooling is then applied over the feature maps for invariance to translation. Pooling is based on the concept that when we change the input by a small amount, the pooled outputs do not change. We can use min pooling, average pooling, or max pooling. Max pooling provides better performance compared to min or average pooling.
Flatten all the input and pass these flattened inputs to a deep neural network that outputs the class of the object
The class of the image can be binary like a cat or dog, or it can be a multi-class classification like identifying digits or classifying different apparel items.
Neural networks are like a black box, and learned features in a Neural Network are not interpretable. You pass an input image, and the model returns the results."
This means that actually we have not understood how machines learn form the data; we have provided a network architecture and data as learning material but no how the model learns or what the interpretations interpretations really are..
'How does the machine 'see'?'
"Feature Visualization = Feature Visualization translates the internal features present in an image into visually perceptible or recognizable image patterns. Feature visualization will help us understand the learned features explicitly. First, you will visualize the different filters or feature detectors that are applied to the input image and, in the next step, visualize the feature maps or activation maps that are generated."
As I understand it this means that the computer itself doesn't have any visual form of 'seeing' it only processes in binary 0 - 1 and we need the 'feature visualisation command/step' to make it visual for US.
"Visualizing Feature maps or Activation maps generated in a CNN
Feature maps are generated by applying Filters or Feature detectors to the input image or the feature map output of the prior layers. Feature map visualization will provide insight into the internal representations for specific input for each of the Convolutional layers in the model."
This breakdown of how images are processed and 'understood' by the machine can play an important part in my film and the visualisation of the dataset.
https://towardsdatascience.com/convolutional-neural-network-feature-map-and-filter-visualization-f75012a5a49c
In Handwriting analysis "For training an ANN model, varied datasets are fed in the database. The data thus fed help the ANN model to differentiate. ANN model employs image processing for extraction of features. " > EXTRACTION OF FEATURES
> From this statement it makes sense to say that object categorisation / image detection is the main issue or the first visual hurdle of AI and thus a good point to focus on also in my work and what my COMPUTER'S VISION IS / how is the network looking at the dataset.
"What is ImageNet?
ImageNet is an image dataset organized according to the WordNet hierarchy. Each meaningful concept in WordNet, possibly described by multiple words or word phrases, is called a "synonym set" or "synset". There are more than 100,000 synsets in WordNet; the majority of them are nouns (80,000+). In ImageNet, we aim to provide on average 1000 images to illustrate each synset. Images of each concept are quality-controlled and human-annotated. In its completion, we hope ImageNet will offer tens of millions of cleanly labeled and sorted images for most of the concepts in the WordNet hierarchy...While the field enjoyed an abundance of important tasks to work on, from stereo vision to image retrieval, from 3D reconstruction to image segmentation, object categorization was recognized to be one of the most fundamental capabilities of both human and machine vision. Hence there was a growing demand for a high quality object categorization benchmark with clearly established evaluation metrics. "
"The most highly-used subset of ImageNet is the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012-2017 image classification and localization dataset. This dataset spans 1000 object classes and contains 1,281,167 training images, 50,000 validation images and 100,000 test images. This subset is available on Kaggle."
There is the distinction between 'training data' and 'use case data' for image recognition i.e. other visual task I can decide between.
https://www.unite.ai/modeling-artificial-neural-networks-anns-on-animal-brains/
"Zador believes that one thing that could come from genetic predisposition is the innate circuitry that is within an animal. It helps that animal and guides its early learning. One of the problems with attaching this to the AI world is that the networks used in machine learning, ones that are pursued by AI experts, are much more generalized than the ones in nature.
If we are able to get to a point where ANNs reach a point in development where they can be modeled after the things we see in nature, robots could begin to do tasks that at one point were extremely difficult."
Furtehr indication of what a dataset looks like over ImageNet on Kaggle: https://www.kaggle.com/competitions/imagenet-object-localization-challenge/data
'How does image recognition work?'
When it comes to identifying and analyzing the images, humans recognize and distinguish different features of objects. In contrast, the computer visualizes the images as an array of numbers and analyzes the patterns in the digital image, video graphics, or distinguishes the critical features of images.
Image recognition is a technology that enables us to identify objects, people, entities, and several other variables in images.
Image recognition is a sub-category of computer vision technology and a process that helps to identify the object or attribute in digital images or video. However, computer vision is a broader team including different methods of gathering, processing, and analyzing data from the real world. As the data is high-dimensional, it creates numerical and symbolic information in the form of decisions. Apart from image recognition, computer vision also consists of object recognition, image reconstruction, event detection, and video tracking.
Depending on the type of information required, you can perform image recognition at various levels of accuracy. An algorithm or model can identify the specific element, JUST AS IT CAN SIMPLY ASSIGN AN IMAGE TO A LARGE CATEGORY.
So, you can categorize the image recognition tasks into the following parts:
_ Classification: It identifies the “class,” i.e., the category to which the image belongs. Note that an image can have only one class.
_ Tagging: It is a classification task with a higher degree of precision. It helps to identify several objects within an image. You can assign more than one tag to a particular image.
_ Localization: It helps in placing the image in the given class and creates a bounding box around the object to show its location in the image.
_ Detection: It helps to categorize the multiple objects in the image and create a bounding box around it to locate each of them. It is a variation of the classification with localization tasks for numerous objects.
_ Semantic Segmentation: Segmentation helps to locate an element on an image to the nearest pixel. In some cases, it is necessary to be extremely precise in the results, such as the development of autonomous cars.
_Instance Segmentation: It helps in differentiating multiple objects belonging to the same class.
How does Image Recognition Work?
As mentioned above, a digital image represents a matrix of numbers. This number represents the data associated with the image pixels. The different intensity of the pixels forms an average of a single value and represents itself in matrix format.
The data fed to the recognition system is basically the location and intensity of various pixels in the image. You can train the system to map out the patterns and relations between different images using this information.
After finishing the training process, you can analyze the system performance on test data. Intermittent weights to neural networks were updated to increase the accuracy of the systems and get precise results for recognizing the image. Therefore, neural networks process these numerical values using the deep learning algorithm and compare them with specific parameters to get the desired output.
Scale-invariant Feature Transform(SIFT), Speeded Up Robust Features(SURF), and PCA(Principal Component Analysis) are some of the commonly used algorithms in the image recognition process. The below image displays the Roadmap of image recognition in detail.
JUST AS IT CAN SIMPLY ASSIGN AN IMAGE TO A LARGE CATEGORY. > THIS SOUNDS LIKE THE TASK THAT WILL BE VISUALISABLE AND RELEVANT FOR MY VIDEO.
I.E: CLASSIFICATION
In the end a Dataset is also JUST a form it takes on. A process of archiv-isation and visualisation and it can take on multiple forms. Or rather it's at it's core just a collection go input imagery in a computer Folder.
This open source Framework and Toolbox ( with "a huge range of sophisticated animal vision modelling and analysis tools") is developed for image analysis to help us humans see like animals / understand animal vision. Which is a variation in a way of what I am speculatively doing. Via this already developed and use-able Framework the steps that the images need to go through to become read-able by the machine become clearer!
In my video it will be valuable to show also the reductionist steps that have to occur when preparing the data for the machine's processing.
With this digital toolbox I can see what preparing the images for a computer system/framework can look like and how the machine breaks it down and looks at it.
This leads right into how the machine sees and processes the images. What Filters are used to break it down etc..
Here its:
Taking images > conversion to animal vision through a machine that has the input information on what animals see like to create a new image
My version:
footage that shows animal vision in a subjective way > as input for the machine > which also needs to be prepared for the machine's perception.
But essentially it's also a computer framework looking at input images with the overall theme of 'how do animals perceive'
What it#s about "To understand the function of colour signals in nature, we require robust quantitative analytical frameworks to enable us to estimate how animal and plant colour patterns appear against their natural background as viewed by ecologically relevant species. Due to the quantitative limitations of existing methods, colour and pattern are rarely analysed in conjunction with one another, despite a large body of literature and decades of research on the importance of spatiochromatic colour pattern analyses. Furthermore, key physiological limitations of animal visual systems such as spatial acuity, spectral sensitivities, photoreceptor abundances and receptor noise levels are rarely considered together in colour pattern analyses."
Which basically means here it was necessary to use these digital visual modelling steps to have a real analysis based on another species view on these patterns and not the human view.
source: https://www.biorxiv.org/content/10.1101/592261v2
Personal note 07.04.22 : my style of work is somehow comparable; using the theme as a concept to then create a 'finished artwork' ( I can stand by that approach - even if it is not Ursula's way)
*In this process here: basically creating images for the process / basically creating a Dataset for this further analysis process; ideally the animal's vision is ALREADY largely to be considered - so that the Framework can then build on this ideally already close to the animals-vision imagery.
BASICALLY CREATING A DATASET IN CONSIDERATION OF ANIMAL VISION
" Following calibration the image pixel values are scaled to percentage reflectance (in red, green and blue, in camera colour-vision) relative to the grey standard(s) in your image."
> This starts to give an idea of how images are turned into a pixel format
I found this graphic visualisation of human vision very interesting in the further development of how the machine looks at the data..
It's astonishing how we 'assume' and translate everything in nature to math i.e. a level of numerical abstraction that appears to actually be so true that we can use observations from nature to math into a form of executing/ task-capable 'computer/artificial intelligence'
There is a significant parallel when reading about how research is done to retrieve 'facts' about animals. Because we are calculating, trying to reduce rules and patterns and structures from what is observed / the inputs, which is the same process the machine undertakes in machine learning.
The facts that in my concept all audio-visual information is pure Data or transferred to data also speaks to our hyper-digitalised Media-culture; just the fact that so many films are largely CGI over 'real sets' draws some parallel to me.
source: Ephemeral Ontologies - Luc Courchesne https://vimeo.com/397464598
source: www.mygreatlearning.com
source: https://ars.electronica.art/center/de/neuralnetworktraining/
Multiple things about this endeavour are great because they are really fitting to my project and reassert the relevance of what I am doing, while also affirming some choices have made so far.
(1)
The circular screen set up shows that a circular positioning can also be useful and appropriate in Data visualisation, when you need to see a lotto inputs at once.
(2)
New information on Convolution Filters and literally the formulation " Wie Convolutional Neural Networks sehen" - which draws the parallel to animal intelligence/perception and especially vision.
(3)
A Neural Network actually trained "Aus der Sicht einer Maus " eine Situation einzuschätzen.. which could be precisely the process my speculative dataset could be used for (an idea for how I present the dataset in the end) and it's really exciting to see that such adjacent use cases are developed ALREADY.
source: https://artificial-senses.kimalbrecht.com/
"The entire orientation of a machine towards the world is mediated by numbers. For the machine, reality is binary—a torrent of on and off. Any knowledge about the world that we learn from the machine goes through this process of abstraction. As we become more dependent on our machines, we need to understand the underlying limits and boundaries of this abstraction."
source: https://ars.electronica.art/center/de/computer-vision-fails/
"Scharen von Microjobbern aus Afrika, Indien oder China widmen sich der Aufgabe, Tausende Bilder für das Training neuronaler Netze zu durchforsten und genau zu kennzeichnen."
My conceptual analogy is mirrored in how the AI systems are designed i.e. there is this analogy to the biological seeing and learning
"Convolutional layers convolve the input and pass its result to the next layer. This is like the response of a neuron in the visual cortex to a specific stimulus. "
WHAT IS MY DATA USE CASE?!!!?
source:https://ev.is.mpg.de/
Do I maybe even want to show biological cells/neurons and energy transfer and transfer to artificial neural network in some model visualisation?
"Typically the task of image recognition involves the creation of a neural network that processes the individual pixels of an image. These networks are fed with as many pre-labelled images as we can, in order to “teach” them how to recognize similar images."
Great article:
https://www.mygreatlearning.com/blog/image recognition/#:~:text=into%20various%20categories.-,How%20does%20Image%20recognition%20work%3F,how%20to%20recognize%20similar%20images.
source: https://ars.electronica.art/center/de/exhibitions/ai/
"Convolutional Network für die Wahrnehmung der visuellen Welt. Wir haben 1000 vordefinierte Objekte und das Netzwerk ist dazu trainiert diese Objekte zu erkennen. CNN ist maßgeblich verantwortlich für die Fortschritte im Bereich Deep Learning in den letzten Jahren. Die selbe Technologie die in selbstfahrenden Autos zum Einsatz kommt; Überall wo es darum geht die visuelle Umwelt wahrzunehmen benutz man diese Technologie. Das besteht aus verschiedenen/mehrere Layers/Schichten und jede Schicht lernt bestimmte visuelle Merkmale von dem Bild. Ganz am Anfang haben wir den Input, das ist ein Bild bestehend aus Pixeln, und die ersten Layers, die lernen sehr primitive Merkmale wie zum Beispiel gerade Linien, Kurven, Farben, solche Sachen, und Sie geben diese Information weiter an die nächsten Schichten. Wenn Sie das Netzwerk anschauen werden sie feststellen, dass die Information immer abstrakter und abstrakter wird. Irgendwann haben wir dann nur noch Noise oder Sachen die für uns keinen Sinn ergeben aber für das Netzwerk beinhalten sie eine bestimmte Information.
Es ist inspiriert davon wie das Gehirn funktioniert, es geht darum wie das Gehirn die Information von der Umwelt wahrnimmt und bearbeitet ."
Comment AI - Beteiligung der Besucher in dem Labeling/Beschriften von Datensatz
Die Wichtigkeit der Daten auf dem Netzwerke trainiert werden, Sie sagen sehr viel aus.
Deep Space 8K des Futurelab
source:https://ars.electronica.art/futurelab/en/research-poetic-systems/
"Technically speaking, Deep Learning models can only learn the statistical patterns of the data. Thus, they often can learn relationships in the data that human observers have not been aware of"
*Might make a lot of sense to try to run some code for StyleGAN or other prior to talking to researcher & scientists so I know a bit more what I am talking about.
Could also be very possible to do the visits regarding AI after shooting as it will more so influence the way I do the data-visualisation.(Good of course to be absolutely certain what I need in this department as well before starting to shoot.)
+ Do I want additional data (e.g. biological information) to be visualised in text or graphs on the image as well?
Data input used for Robotik systems to understand the environment?
I hadn't though about robots but the more I read on the research groups it appears that this embodied approach is also very relevant in the research field and applications of AI.
"It invites viewers to inspect what was lost in computational translation and at the same time imagine a vision that surpasses human gaze."
- p.31 slanted Ai edition
This I think is a very valuable reference when it comes to visualising the dataset.
" Using simplified examples, Neural Network Training shows how long operation chains of mathematical functions operate as so-called artificial neural networks. Named after the leading cells in nervous systems and inspired by them, these networks organize data input into tendencies or probabilities and categorize them. Various networks can be both trained and observed in their application at the Ars Electronica Center.
At the end of the educational series, the Ars Electronica Futurelab illustrated various steps in the categorization of a Convolutional Neural Network (CNN), one of the basic building blocks of AI technology and deep learning. During the training phase, different characteristics of images were learned in several filter layers, i.e. simple lines, curves and complex structures are arranged independently and form the basis for categorizing images. These successive filters are visualized on eleven large displays in the Ars Electronica Center. At the end, a percentage diagram shows the the AI system’s assessment of one of the objects shown on the built-in camera.."
source:https://ars.electronica.art/futurelab/de/projects-understanding-ai/
https://ars.electronica.art/futurelab/de/projects-understanding-ai/
https://ars.electronica.art/aeblog/de/2019/08/06/understanding-ai-futurelab-installations/
"Neuronale Netzwerke sind eben nichts anderes als eine Anhäufung von vielen Schaltern, die sich immer wieder neu einstellen – wie unser Gehirn eben auch. Bei uns bilden sich Synapsen, so etwas ähnliches passiert zwischen den künstlichen Neuronen."
THIS CAN BE AN AVENUE FOR VISUALISATION!!
https://ars.electronica.art/aeblog/de/2019/08/06/understanding-ai-futurelab-installations/
https://datanutrition.org
A dataset on animal perception can allow AI to process animal intelligence from a non-human perspective and opens up possibilities for a much deeper understanding of the animal kingdom, which ultimately can advance animal studies and insights from animal behaviour (like at CASCB) that can create innovative solutions for humanity.
Idea: overlay of text that shows what insights the data the audience sees contains for the machine. This would be highly future-speculative, because right now the AI process is solely VISUAL PROCESSING. The meaning is created through repetition, not through deep content of a single data file.
The ANNs processing will be primarily numeric and deal with matrixes - this can be an inspiration for how to design the matrixes
In how I 'design' the dataset I can emphasise the idea of networks between the animals.
In how I 'design' the ANNs processing and computer vision process I can create a similarity to human vision
Considerations on REAL-LIFE perception are also missing in the development of computer vision.
From this talk emerges the idea that my dataset could be important for a robotics use case of 'being in the world' for 'action'
But my work is really not about a real task or real use-case. It is about setting animal perception and computer perception side by side. It is about showing the origin and the future.
As Computer scientists have the goal e.g. of autonomous self driving cars and robotics my intention as an artists is to provide this dataset to question our understanding of intelligence and break down vision and perception from biological to artificial . I want to provide audiences with an enriched understanding of perspective on being in the world including artificial intelligence systems that will continue to heavily shape our future.
The aim of my dataset lies outside of the film's plot narrative.
I also 'just' hope that this might inspire future research
Here the ANNOTATION /the importance of LABELLING of Datasets is talked about. This is something I need to include because without labels the Data is not useful to the system.
THOUGHTS ON MEANING: We always think 'O how could this be useful for humans' like tracking all pixels in a video that shows urban scenes of buildings, cars, humans can easily be justified . Instead of finding a plausible use-case for my dataset that would make humans accept it more easily the work is exactly about challenging this human-centric view and opening up towards the co-equal inclusion of other lifeforms and how their landscape and surroundings look as being important as well. Such dataset gives equal importance to the POV of other nonhuman animals, giving them a space in out increasingly digital world. Because I DO see a problem in developing AI systems trained only to see the world through human eyes, because there are so many more perspectives to be considered in future decisions concerning life on our planet.As we move towards more and more digital living it is important to include animalistic perspective 'closer to nature'. Breaking open the human-centric view of intelligence primarily reserved only to humans and now artificial intelligence that is only informed by and serving humans is very important to create a future-inclusive-mindset.
But if you really needed a use-case for example it could be not about self-driving cars but robotic bees.
More generally these new kinds of datasets push towards bringing computer vision closer to human vision.
Why am I even comparing the animal to the artificial? To show the similarities, so it makes sense, to emphasise the neural basis of ANNs in my visualisation.
Datasets are generally used to train/teach computer models to 'understand' something about the real world. The data sets contain some information about the 'real world' that serve some purpose of human interest.
My dataset steps outside of the typical profit seeking approach/mentality and suggests the importance of teaching multiple biological perspectives.
In our real world animals exist as agents, moreover, everything exists with an inside life that goes beyond their mere outline. In the digital animals exist only as outlined representation. My data set shifts the attention towards the importance of including things beyond their mere outlines in the digital realm.
Thoughts on this study: https://ps.is.mpg.de/publications/geiger2015gcpr
Computer science research geared towards closer connection to natural systems and intelligence of bio-inspired systems
source: Ryoki Ikeda - Almine Rech Paris https://www.youtube.com/watch?v=3YgeU19N3WE&ab_channel=AlmineRech
source: Neural Networks 3D Simulation
source: Misaki Fujihata - Simultaneous Echoes 2009
Artistic Direction Insight: Ryoki Ikeda's world of data visualisation is much more mesmerising , it brings a viewer into the 'awe' of realising that computers function so much differently from how we do. That their way of being is so different from ours. This is the realisation thatI am trying to achieve that will only strengthen the 'otherness' of the animal's perception as well.
Artistic Direction Insight: This is more a form of 'data visualisation' / visual archiving FOR HUMANS. But we aren't trying to explain it for humans. We want to dive into the computer's perception. Just as we tried to dive into the animals.
This is also more of an 'explanatory view from the outside'
Ikeda dives inside. "you are forced to jump into the super highway of zeros and ones'
The 2D visualisation underlines the 'otherness' immediately because we humans and animals live in a 3Dimensional world but Computers live in a binary world of numeric values, matrixes and pixels. Their image space is not 3 Dimensional.
This also reminds me of my earlier thoughts on the project and the 'flattening' of information as it spans from the multi-sensory, multi-species world of animals, over to the singular human and onto the binary machine. This flattening of information SHOULD be made tangible through the 2D space.
BUT, would the 2D quality of computer vision possibly become even more clear if there is a 3D- dataset potion in between? #
'DATA-VERSE'
Collaborate with Computer graphics programmers? Is it possible to really pull the visualisation of how the machine 'sees' my video files from the machine itself?
Not to 'design' the computer vision but actually have it straight from the machine itself?
(Do I have time for such an approach?)
"Entwickelt Programme ( Pure Data?) die jede beliebige form von information in visuelle und akustische motive umwandeln können"
source: Ryoki Ikeda https://www.youtube.com/watch?v=jCR7KJQtwGE&ab_channel=FACTmagazine
source: Ryoki Ikeda https://www.youtube.com/watch?v=J9HieZOpAzM&ab_channel=ArteTRACKS
"allow viewers to visually and acoustically experience digital universes.(...)
Ikeda succeeds in making the abstract volumes of data and computing power we deal with every day comprehensible. He lets viewers immerse themselves in digital universes, which oscillate between the smallest measurable units, i.e. bits and bytes, and cosmic dimensions—they give the impression as if, with the data streams, one were on a journey through space.
The pulsating sounds underlying the installations range in their spectrum from barely audible sine tones to dull, physically perceptible bass sounds. The latest 4K projection technology contributes to transforming the exhibition into a fascinating total synesthetic experience." 'Data-verse' Exhibition -source:https://www.kunstmuseum.de/en/exhibition/ryoji-ikeda-data-verse/

In the'Data-verse' exhibition works Ikeda collages the data-visualisation with imagery of the universe (outer-space). It is quite straight forward but maybe if you want to get the idea across it does work to be more direct and literal at times.
"Ikeda has found an audiovisual language to capture the frantic processing of computers, ferociously producing and consuming data. Computers, however, are no indifferent entities in the world of Ikeda. They can be merciless machines that devour code, sure, but within that electronic aggression may reside a sense of beauty and a glimpse of the sublime. " - https://www.rewirefestival.nl/feature/ryoji-ikeda-transcending-0s-and-1s
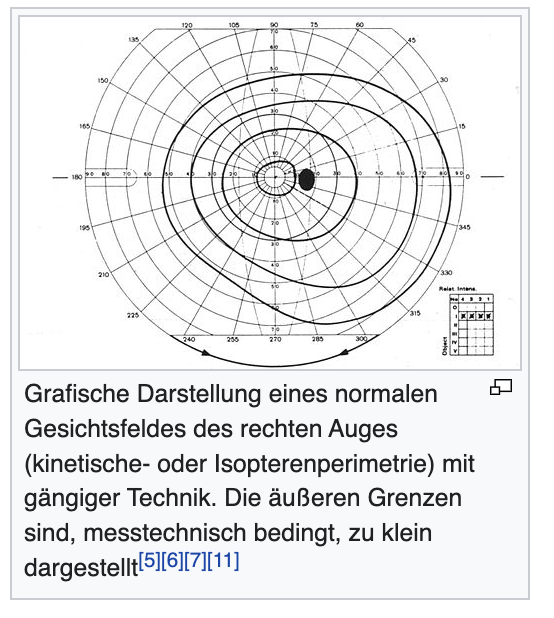
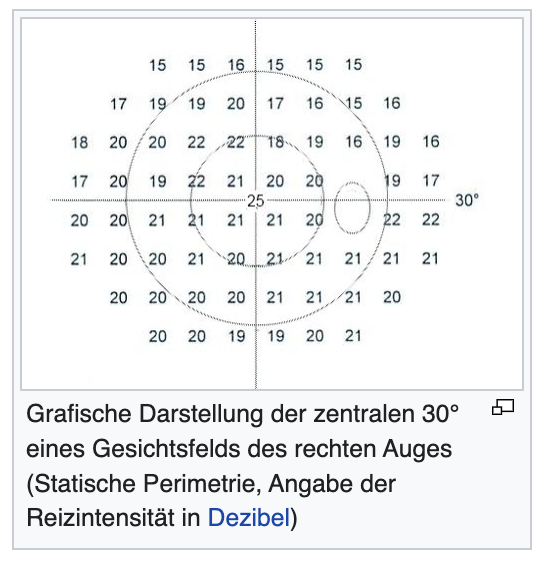
Überlegungen zum Sehen und Gesichtsfeld der Tiere haben das Video-Bild vorrangig bestimmt
demnach macht es Sinn diese Betonung auch in der Daten-Darstellung mit aufzunehmen.
"Man unterscheidet das monokulare Gesichtsfeld des jeweils rechten und linken Auges allein, vom binokularen Gesichtsfeld, das die Summe der beiden monokularen Gesichtsfelder ist. "
multiple types of collage could take place
collage in the meaning of the structure , the form of the architecture
added meaning and depth of additional data of the dataset, on an image level , collage of e.g. 'Gesichtsfeld graphics' on top of the video image
*There is also a type of collage taking place when looking at the overlap between (1) that humans use numbers and graphs to make data about a topic graspable (2) machines use numbers in matrixes when processing information. These is a visual language here that people recognise and I could play on this by integrating graphical, numeric representations of the topics the work deals with into the design of the machine layer perception
Die Breite des Sehfeld eines Tier könnte zB mit der Ausbreitung der Daten-dateien auf dem Bildschirm korrespondieren.

We won't be looking at the architecture from outside, once we are in the computer vision - ANN processing it's not about explaining some architecture (because there are so many different models and we aren't making an explain video). Instead we are DIVING Into the binary nature of computer code.
source: https://de.wikipedia.org/wiki/Gesichtsfeld_(Wahrnehmung)#:~:text=Darstellung%20des%20Gesichtsfelds,-Grafische%20Darstellung%20eines&text=Im%20Zentrum%20liegt%20die%20Stelle,vertikalen%20Meridian.
Possibility to add data visualisation that adds a transparency into how the video sequences are developed based on this data and how that could co-exist in this data processing we envision in a more holistic approach.
source: https://towardsdatascience.com/a-gentle-introduction-to-neural-networks-series-part-1-2b90b87795bc
It's less about accuracy of the exact process but accuracy of the impression.
Start in the digital > deep dive into the digital > then deep dive into the animal. This is what I want people to feel when viewing the installation,
Inspired by the start and how to 'start the journey' by entering into the digital. Also inspired by the SOUND that sets the scene and gives a void-like sound to the digital space, before the submarine like echo starts.
While inspired by the feeling if delving into the machine binary code world I am not interested in using these stylistic devices, no white noise, no big rush of data, no general abstraction and general abstractness. I want mine to be a bit closer to the process of ANNs and computer vision, (not how do computers compute in general).
What his work also shows me is that there is quite a lot you can get away with, because strictly analysing the visual decisions it's quite freely interpreted with collage of point cloud like data mit grids with matrixes to create a technical appearance, while there might not be any real correlation between the image layers.
Moreover, the main perceptible reference is from a u-boot, the old-fashioned echo like orientation of a light ray across the screen and the clearly related sound scape that characterises all of his work in this actually very illogical sound for data processing.
This has more of a 'universe -galaxy' impression, whereas, if anything, I want a neural brain network impression. But also this image below, which looks a bit like what I imagine a brain scan could look like and has a more organic quality doesn't feel appropriate. Maybe it's too literal? Maybe it's trying too hard? Maybe it's not matching my flavour of conceptual?
As a guiding principle the MYSTERY that I seek to create in the video animal sequences I also should seek to continue in the AI animation.
In the end it needs to be aesthetically appropriate and balanced to the footage we created already.
"Wenn auf einmal man versteht das wir immer versuchen die Machine zum denken zubewegen aber andererseits wir mMenschen versuchen immer mechanischer zu werden. " - Carsten Nicolai
Google page: https://experiments.withgoogle.com/visualizing-high-dimensional-space
Github code for Tensorflow: https://github.com/tensorflow/tensorflow
At Google ' the Big Picture group' works on data visualisation: In the work-field the visualisation of training data is very called for to give an insight into the model. If outcomes arenÄt as expected this can come from the training data, so 'debug your data before you debug your model'. For this data visualisation is fundamental.
By having the possibility to look at your data you can adjust for mistakes that creep in.
There is also not ONE WAY of visualising or organising the data. But it is just one 'vast pool' until such visualisation takes place.
Data is HIGH DIMENSIONAL in the Machine Learning Model - World.
Location has a meaning in high-dimensional space. Information contained in the data decides it's positioning in the high dimensional space.
What happens in visualisation is connecting the dots of the positioning in high dimensional space.
Image is understood as HIGH DIMENSIONAL VECTOR; count the pixel and depending on colour of pixel I assign a value from 0 - 1 ; 0= all white 1 = black , I come up with a vector; boom the image is turned into math
The key to data visualisation is to take numeric values and think of them as points in space. But dies the machine do/need this?
Images are points in 3000 dimensional space
The possibility to actually use a tool to create ACTUAL high-dimensional data-points literally from my data as JPEG thumbnail
A core concept of machine learning: high dimensional space >> so the computer's world in machine learning is multi-dimensional
Machine Learning sees dimensions as numbers, and each set of numbers as a data point, by looking across all these dimensions at once it is able to place related points closer together
When using images as inout the computer treats each pixel as a dimension and an image has 784px
In computer science practice image datasets are visualised in 3 Dimensional space!
I need to talk to or collaborate with data-visualisers
What would happen if I actually put Jpegs from my dataset into this data visualisation tool using T-SNE:
I would get an impression of how the system sees my Data..
Probably I would get clusters of my entire JPEG sequence if I put it in..
What else would I get?
I SHOULD DO IT!!!
Why invent some kind of new visualisation? Why not 'just' stylise differently exactly such visualisation being used in machine learning research?

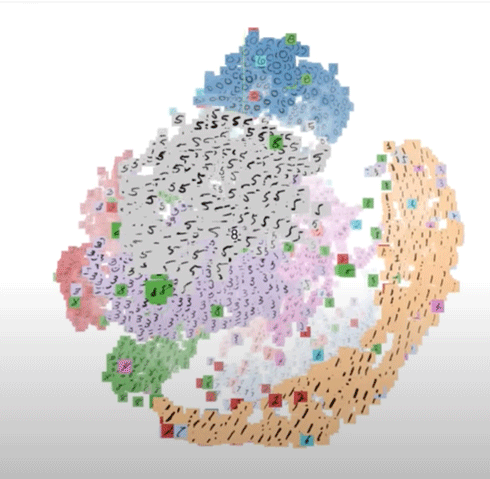


First and Foremost Data visualisation is a tool FOR HUMANS to understand better the computers processing. It doesn't mean that the computer needs the high-dimensional space visualised to work in it.
Nonetheless visualisation is used in computer science and choosing such presentation does give an accurate insight into the field. I could argue that in the animal representation the human-hand in it could not be omitted. As an equal to that I choose to also allow the human-made-ness of AI systems and our efforts to understand them shape my presentation of these systems. I choose not to omit the human in this representation.
Data visualisation can give insight into how models process i.e. 'understand' their input data e.g. the multi-language translator tool from Google that 'learned' the actual meaning , the semantics of words which lead to zero-shot learning i.e. being able to translate between two languages despite paired training data for their translation.
Visualisation gives a sense of the landscape of these multi-dimensional spaces. I like the key word of 'landscape' as this overlaps with the animal's landscape. 'A crashing together of animal's landscape in the data, which the ML model landscape when processing the data'
These models allow humans to '"see kind of like an MRI version of this net" - again the similarity in phrasing and understanding is very brain based.
An interesting idea presented here is that a processing via T-SNE ( what is TSNE - is it an algorithm Because then my thought would be that a neural nets processing could already be represented in the one organisation of the dataset as opposed to showing two somewhat separate processes; the processing and the dataset.
"T-SNE has an almost magical ability to create compelling two-dimensional “maps” from data with hundreds or even thousands of dimensions. Although impressive, these images can be tempting to misread. The purpose of this note is to prevent some common misreadings."
> This gives a sense of the DESIGNED ELEMENT OF SHOWING THE DATA. THIS TOO IS A CODED, 'DESIGNED' PROCESS.
'Data visualisation for AI Explainability'
The challenge is understanding what is being learned by these systems. I could just keep it not understood. Create a computer world incomprehensible to humans. WE STILL DON'T REALLY KNOW WHAT HAPPENS INSIDE THE HIDDEN LAYERS.
Am I capable/ do I want to try to not visualise these systems. To really emulate the machine learning pipeline through the computer's perception that we don't understand?
I think at this point I've moved away from wanting to show image recognition tasks because it just doesn't fit my dataset which is much smaller and more dense as a small size video dataset. IT#s not really about showing an explcicit process but showing the machine's processing in general. However, this can be easier when having a specific pipeline to orient along.
It still isn't clear to me what are the features that the projection software organises the data on? What is it asked/programmed to look for?
DEPICTING DEEP LEARNING ARCHITECTURE
"Networks are complex, massive (sometimes) and have lots of high degree nodes, all the low level nodes, all the edges in a network. into something much more structured, that takes into account hierarchies, that takes into account high degree nodes and how you should deal with that for the topology of the network.
This is the level that WE AS HUMANS want to think about these systems, in diagrams that are graspable for us. Such diagrams are very useful for humans to talk and think about these things and develop and understanding for the process. But I want to develop an understanding for the machine and how the machine actually processes instead of making an individual process understandable to my audience.
Google's Tensor Flow creates graphs for networks given to it, as a form of visualisation service. I can sue this as orientation should I choose a neural network to show. : A Data flow graph.
A tensor = a multi dimensional array : tensors are visualised as line paths ta are labeled with their size e.g. 128 x 24 x 24 x 64
They don't show their entire organised graph at once because even this would be "completely impossible to read"
There are always nodes in the system that connect to everything else, like gradients and since you just can't read a graph like that they applied a bunch of tricks; mainly they introduced AUXILLARY nodes to trim-out parts of the system BECAUSE OTHERWISE IT IS IMPOSSIBLE FOR HUMAN'S TO READ. Their main aim in communication between humans.
I'm not trying to explain the image recognition /ML process as good as possible; if so I should have stayed close and scrapped a dataset form the Internet and used 32x32px sized images to show the image recognition process. But I developed a cinematic dataset because it is about the higher level topics. To stay true to this higher-level I should try to get as close to the machine as possible with respect to the limitations of being a human, just as we did for the animals. I should mirror this approach.

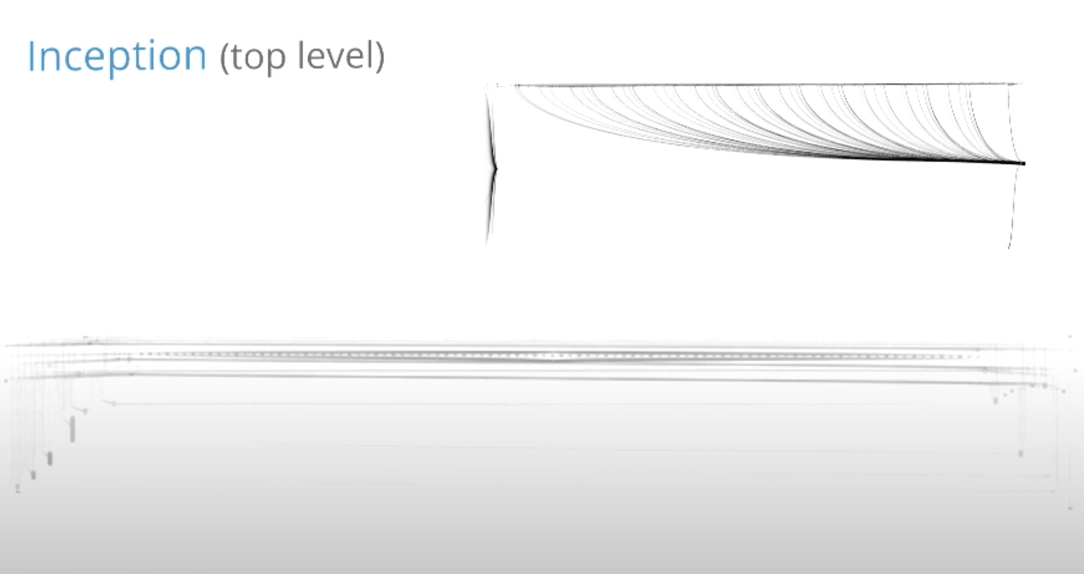
This is what one of the networks looked like without any of the trimming.
components ARE two-fold: 1) the networks, the systems, the algorithm 2) the data
The use of SPEED is also a way to show the fast-pace, hard-to follow processing of machines as opposed o humans.
In my human intuition I immediately want to organise it so that I can understand it. Maybe I need to resist that urge?
> Find a balance between instances that give a sense of what might be happening while at the same time focusing on mainly getting the feel of computer processing across. Giving a 'truer artistic sense' that isn't about explaining it but about giving a feel for it.
source: https://quadrature.co/work/orbits/
Yosinki - 'DeepVis' Toolbox for visualisation of layers in a convolutional neural Network
All these elements that you see here they are all designed and 'made-up' as well and the audience buys it. So it really is possible to create this space where design decisions are not 'traceable' in a way anymore and it becomes so convincing that people feel like they are getting this 'raw sense of the machine'. But this of course is designed too.
This article makes me think not that I should use such 'psychedelic' 'deep dream' visualisation but that the key characteristic that distinguishes NEURAL NETS FROM ANY OTHER COMPUTER PROCESS ARE DETECTION FILTERS and by visualising these I am 'already' full-filling a key step in identifying neural nets.
One second after I'm thinking: I could use deep dream generator to create filter detection layers (possible corresponding to my image inputs' - I could try to reverse engineer. Is it possible to create an animation of these filters forming?
But immediately when taking a closer look at 'deep dream generator' it becomes clear that this is a user_friendly made tool for style-transfer and has little to do with looking into the machine hidden layers: https://www.slaphappylarry.com/using-artificial-intelligence-to-make-art-wombo-and-deep-dream-generator/
I can load the images from my dataset to this tool and get the reaction of every layer / neuron!
Probably I would get out something like this. Which I could work into a graphic representation something like this:
Generally this starts to show me: YES I CAN DEFINITELY RUN CODE AND USE VISUALISATION TOOLS OF THE COMPUTER SCIENCE FIELD TO CREATE THESE VISUALS.
Try it: https://yosinski.com/deepvis
The similarity in these visualisation is a clear sign of our similar attempts at understanding and our similar understanding of these instances. It doesn't necessarily mean that they are so similar but certainly our attempts at understanding them are.
What I find interesting here is that we move from a 3D-ish visualisation, moving around this type-of-point-cloud, made of line structures, into a fully line based 2D rush. But upon further inspection it might be linked that the lines in the 2D are the same lines as the scanner line we see in the 3D cloud. I like this sort of doubling and scaling at different perspectives and I might like to do something like this but make it more linked i.e. more clear that this is the same section or process of the computer but in different visualisations or proximities.
I really like this visualisation from 02:24 - 03:12
"Last layer of the network: compact representation of the content of the image"
MAYBE INSTEAD OF SETTING OUT TO SHOW ONE NEURAL NET PROCESS I MAKE A PORTRAIT OF VISUALISATION TOOLS AND ATTEMPTS FOR DEEP NEURAL NETWORKS ..
I use these tools to pull out actual processing data from neural nets in response to my data. So I use neural nets to show what neural nets do.
A strong feature here are the 'labels' - numbers running and giving a sense that computation is happening.
I think to show these filters with 'traces' of my dataset imagery as ghostly shadows coming together will really make it clear that the computer is processing the image.
Like in 'data-verse 1' There could be a flashing sequence of the dataset ( for which we would have to stitch more of the takes for ONE SINGLE FRAME and then transition to the 3D clustered Dataset and then possibly identify one file in the dataset as input for the neural net and follow it's journey through the nets processing.
It's all a question of visualisation but if I use the tools actually being used in computer science and put them in an
artistic context I think I'm going the right route.
What is Machine language
link: https://www.computerhope.com/jargon/m/machlang.htm
Compile is the creation of an executable program from code written in a compiled programming language. - https://www.computerhope.com/jargon/c/compile.htm
https://www.nature.com/articles/d41586-020-02947-5
And to get a truer sense of how computer vision algorithms work I could try to run them using Tensorflow > from this experience I can better create a mirror of that process. > So really integrate these processes I am showing in the research ( not just secondary) Do the primary research here!
There are two kinds of visualisation:
(1) What does it look like when you try to explain in to a 'ordinary person'; an over simplified 'explain graph or video' - that shows the overall structure without any detail.
* also, I don't feel cognitively capable of understanding all these filters and to actually visualise what is happening here seems to be impossible - even for Google's Expert teams - so at this point it is rather about developing a basic understanding that allows me to make an informed artistic decision.
(2) What does it look like when you dive in; the specialist view, the up-close-view . What do the individual elements look like 'within the system' or even 'as processes/perceived by the system'

The navigation and SPEED of going through this void black space is very 'tour-like' somehow voyeuristic. But in this way it does actually support this feeling of seeing something 'real'. In a way I gravitate most towards this visualisation because it is one I can understand. It is the way a HUMAN would imagine this space.
ERGO: YES I AM ABSOLUTELY SHOWING A DNN/ANN IN A COMPUTER VISION PROCESS
In computer vision, transitioning from black-to-white (0 to 255) is considered a positive slope, whereas a transition from white-to-black (255 to 0) is a negative slope. The image is converted to grayscale and then the gradient of the grayscale image is looked for, allowing us to find edge-like regions in the x and y direction.
Edge detection is used to detect outlines of an object and boundaries between objects (that tend to produce sudden changes in the image intensity) and the background in the image (...)
Edge detection is nothing but a filtering process.
source: https://indiantechwarrior.com/canny-edge-detection-for-image-processing/

Could run this code (filter for edge detection) to show how a neural nets edge detection looks on my input image:
What edges does the computer code detect
With this is becomes strikingly clear that IT IS ALL JUST PROGRAMMED CODE - LINES OF CODE CREATED BY HUMAN PROGRAMMERS IN A LANGUAGE MADE FOR COMPUTERS.
The computer is 'just' computing the code.
It's a machine executing code and 'learning' from the input data.
ERGO: I SHOULD DEFINITELY SHOW THE RUNNING OF CODE AND POSSIBLE ALSO SHOW A DIRECT CORRELATION OF SOMETHING RUNNING AND A RECOGNISABLE ACTION APPEARING IN RESPONSE
Is this the 'edge detection' stage?
I don't really understand this but I guess it is the computation that happens that leads to the type of image output I can get from a filter?
I guess you could say that what happens in between in mathematics in matrixes. < Would a computer scientist agree with this statement? < Ask Fred
Conceptually it could be argued that by showing the dataset in a more hand-made way I am representing the human made element and influence here. Whereas the network itself are also human made but the writing in code totally transports it and the development of these 'hidden layers' makes it increasingly hidden to us what goes on in the network.
Tools like DeepVis Toolbox are essentially attempts to look into what is happening because otherwise we just don't know.

'intelligent agents' = any system that perceives its environment and takes actions to achieve its goals
AI researches extending the concept of what it means to be 'intelligent' beyond the initially human-centric orientation only on the human mind. > more expansive ideas of intelligence extending beyond human forming
Apparently things that are now too 'low level machine learning' are excluded from AI term the better it gets.
Apparently there was a phase tried out and discarded in AI research regarding large datasets of knowledge and imitating animal behaviour. < need to look into this!
AI technology could use other methods but machine learning continues to be most applied, successful. I think in practice AI is mostly ML today but they seem to define AI more like an effort or vision or 'field' than a fully existing practice. ANNs are among several tools that follow the problem-solving goals.
AI research exist without ANNs but they have come to dominate the field.
When I try to get a grip on my Footage I like the idea of showing it as a dataset because I am afraid otherwise people will just not get it. It's a hard to grasp idea and without any visualisation to grasp people will feel lost?
Instructing computers to understand and interpret visual information, and take actions based on these insights is known as COMPUTER VISION. Computer vision is a broad field that uses deep learning to perform tasks such as image processing, image classification, object detection, object segmentation, image colorization, image reconstruction, and image synthesis.
On the other hand, IMAGE RECOGNITION is a SUBFIELD of computer vision that interprets images to assist the decision-making process. Image recognition is the final stage of image processing which is one of the most important computer vision tasks.
The essence of artificial intelligence is to employ an abundance of data to make informed decisions.
deep learning which is an advanced form of machine learning.
Deep learning is different than machine learning because it employs a layered neural network. The three types of layers; input, hidden, and output are used in deep learning. The data is received by the input layer and passed on to the hidden layers for processing. As the name suggests the output layer generates the result.
IMAGE RECOGNITION TASK: The bottom line of image recognition is to come up with an algorithm that takes an image as an input and interprets it while designating labels and classes to that image.
Algorithms make it possible
source: https://logicai.io/blog/using-artificial-intelligence-ai-image-recognition/
PRIMARY RESEARCH: Which programs/code to run?
Some definitions:
Computers interpret every image either as a raster or as a vector image:
> Raster images are bitmaps in which individual pixels that collectively form an image are arranged in the form of a grid.
>Vector images are a set of polygons that have explanations for different colors.
Convolution = combine, bring together, join >> convolve the input and pass its result to the next layer
What to the machine can be identified as a geometric encoding of the images is converted into hand-annotated labels that physically describe the images and give the algorithm possible outputs.
There is always talk of 'architecture' > so as an artist it would be legitimate to use this term and create an algorithm architecture / a neural network architecture ..
I want to show the training phase.
Image recognition refers to technologies that identify places, logos, people, objects, buildings, and several other variables in digital images.
source:https://www.mygreatlearning.com/blog/image-recognition/
Breaking down how the computer 'sees' the input data
A digital image is an image composed of pixels.
Each pixel has a finite, discrete quantities of numeric representation for its intensity or grey level.
>> The computer sees an image as numerical values of these pixels
(from which in the case of image recognition it can recognise the patterns and regularities in this numerical data and compare/assign it to 'learned' prior data)
Let’s go through how a computer views a normal colored image. Essentially, the computer sees it as a bunch of pixels. Each pixel is made up of a certain amount of red, green, and blue light, which your computer quantifies as RGB values.
Because these are the three primary colors, any other color can be produced relative to the amount of RGB light measured. Thus, each pixel has three values measuring the total RGB value. For instance, the color red is represented in RGB as (255, 0, 0). It contains only red light and zero amounts of green and blue light.
The following process - neural network architecture - depends on which computer vision task I show:
If image recognition the steps are wonderfully broken down here: https://www.mygreatlearning.com/blog/image-recognition
This is a really good visualisation that shows me IT'S CODE, its code running that calls a function that says 'dataset download' and then has a folder structure their in which images of a class are in a folder and class folders are in the larger dataset folder AND THAT'S IT.
Any visitation of that space is an ARTISTIC VISUALISATION. It's just codeine a folder.
THIS IS THE INTERESTING -EDUCATIONAL MOMENT - how can I make this computer understanding clear while possible also including a human visualisation to help my audience understand what they are looking at and get the concept across. I think this is the line I have to walk and creatively build the bridge.
"File systems consist of groups of directories and the files within the directories. File systems are commonly represented as an inverted tree. The root directory, denoted by the slash (/) symbol, defines a file system and appears at the top of a file system tree diagram.
Directories branch downward from the root directory in the tree diagram and can contain both files and subdirectories. Branching creates unique paths through the directory structure to every object in the file system.
Collections of files are stored in directories. These collections of files are often related to each other; storing them in a structure of directories keeps them organized.
A file is a collection of data that can be read from or written to. A file can be a program you create, text you write, data you acquire, or a device you use. Commands, printers, terminals, correspondence, and application programs are all stored in files. This allows users to access diverse elements of the system in a uniform way and gives great flexibility to the file system.
Directories let you group files and other directories to organize the file system into a modular hierarchy, which gives the file system structure flexibility and depth.
Directories contain directory entries. Each entry contains a file or subdirectory name and an index node reference number (i-node number). To increase speed and enhance use of disk space, the data in a file is stored at various locations in the memory of the computer. The i-node number contains the addresses used to locate all the scattered blocks of data associated with a file. The i-node number also records other information about the file, including times of modification and access, access modes, number of links, file owner, and file type.
A special set of commands controls directories. For example, you can link several names for a file to the same i-node number by creating directory entries with the ln command.
Because directories often contain information that should not be available to all users of the system, directory access can be protected. By setting a directory's permissions, you can control who has access to the directory, also determining which users (if any) can alter information within the directory."
So I can call up the folder/directory where my footage / 'actual dataset' is stored in my computer in the terminal and actually see what my dataset folder looks like in a non graphical operating systems.
nested like folders and can go down many layers
Calling of the dataset to be used by a CNN literally looks like this:
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical',
subset='training') # set as training data
Model layers look like this
model = Sequential()
inputShape = (128, 128, 3)
model.add(Conv2D(64, (3, 3), padding="same", activation='relu', input_shape=inputShape))
model.add(BatchNormalization())
model.add(Conv2D(32, kernel_size = 5, strides=2, padding='same', activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.4))
model.add(Conv2D(64, kernel_size = 5, strides=2, padding='same', activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(BatchNormalization())
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(10, activation='softmax'))
model.summary()

source:https://www.quantamagazine.org/artificial-neural-nets-finally-yield-clues-to-how-brains-learn-20210218/
Not so similar "For a variety of reasons, backpropagation (used by deep neural nets) isn’t compatible with the brain’s anatomy and physiology, particularly in the cortex."
"Bengio and many others inspired by Hinton have been thinking about more biologically plausible learning mechanisms that might at least match the success of backpropagation. Three of them — feedback alignment, equilibrium propagation and predictive coding — have shown particular promise. Some researchers are also incorporating the properties of certain types of cortical neurons and processes such as attention into their models"
"Each artificial neuron in these networks receives multiple inputs and produces an output, like its biological counterpart . The neuron multiplies each input with a so-called “synaptic” weight — a number signifying the importance assigned to that input — and then sums up the weighted inputs. This sum is the neuron’s output.(...) During training, a neural network settled on the best weights for its neurons to eliminate or minimize errors. "
I think predominantly what this article makes pretty clear is that research do very much orient their research on how the human brain works to develop models for AI.
"By analyzing 1,056 artificial neural networks implementing different models of learning, "< Damn so there are a LOT of different attempts
source:https://bdtechtalks.com/2020/06/22/direct-fit-artificial-neural-networks/
CNN is composed of 2 batch-norm layers, 3 convolutional layers, 2 max-pooling layers, 3 hidden dense layers, 4 dropout layers (used only for the training) and one output layer.
But "the complex deep neural networks that are composed of hundreds (or thousands of layers) and millions (or billions) or parameters." (..) ..have enabled researchers to create and train very large neural networks in reasonable timeframes. And these networks have proven to be remarkably better at performing complex tasks such as computer vision.. But simpler models are also less capable in dealing with the complex and messy data found in nature. < This speaks to the idea of showing a more complex and not simplified for explanation model.
https://datanutrition.org/labels/
"Unfortunately, datasets are rarely complete because the real world has a bad habit of presenting new situations."
Data labelling pipeline using AI -https://www.lifewire.com/ai-can-now-understand-your-videos-by-watching-them-5271437
It's important to understand that these are 'extreme simplifications' to try to understand this otherwise not accessible space.
What also becomes clear is that 'spatial visualisation' of datasets is a issue still being figured out in the field.
https://distill.pub/2016/misread-tsne/
In terms of sound: I like the idea presented here to use the sound from the individual data files BUT ALSO I THINK CREATING A SOUNDSCAPE FOR THE NETWORK IS AN IMPORTANT PART TO GIVE THE ART FILM IT'S ATMOSPHERE AND MAKE IT IMMERSIVE.
(This artwork also presents the option of visualising the dataset in multiple different modes to show that visualisation itself is a choice and thus somewhat arbitrary)
Convolution Layer = A convolution is defined as the simple application of a filter or a kernel to an input image which reduces the number of features of the image by applying kernel and still keeps its important features which defines the image intact. The final target of convolution is to identify all important features of the image by keeping minimum features.
source: https://indiantechwarrior.com/convolution-layers-in-convolutional-neural-network/
If CNN then:
This data-artwork at Ars Electronica Centre shows a way of breaking down and showing the neural nets filters. > This is what I too will be visualising by using my dataset as JPEG Sequence and applying visualisation Toolkits to give me real outtakes of how a neural network 'sees' my input in a (1) image recognition or (2) scene detection or (3) ? -yet to be defined - computer vision task.
MPI Intelligent Systems research:
(1) Perceiving systems Department
Optical Flow for Mostly Rigid Scenes
This method called MR-Flow uses CNNs for Segmentation / to estimate the rigidity maps of moving objects in the video - so is this a computer vision task? The algorithm is using CNNs for a part fo the task but is overall not a ANN - if I understand correctly:
"MR-Flow splits the scene into moving objects and the static scene, uses general optical flow for the moving parts, and strong geometric constraints in the static scene."
Scene Models for Optical Flow
source:https://ps.is.mpg.de/projects/optical-flow-for-mostly-rigid-scenes
source:https://ps.is.mpg.de/research_projects/scene-models-for-optical-flow
I think this might be exactly the kind of computer vision framework geared towards video input consisting of neural networks learning that I have been looking for!
Also the approach to bring together MULTIPLE neural networks goes towards an 'artificial intelligence' approach that exceeds basic machine learning algorithm.
It seems to combine all my key factors!
source:https://ps.is.mpg.de/publications/adversarial-collaboration
The ultimate goal of convolution is feature detection
source: https://medium.datadriveninvestor.com/how-ai-sees-the-world-image-recognition-algorithmic-bias-653890019da0
https://medium.datadriveninvestor.com/how-ai-sees-the-world-image-recognition-algorithmic-bias-653890019da0
Representation of an image when 'went over' with convulsion filter
Representation of a CNN as published in research papers
The code used to run such network.
source: https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
This is fundamental research into how optical flow can be improved for 'natural' video inputs using an 'optical flow algorithm'. Mainly the focus is 'Plane+Parallax framework'
The competitive collaboration framework is strongly linked with scene models for optical flow
What makes this competitive framework really fitting to my film is that it is a more general framework approach that combines multiple neural networks and even gives a structural character to the data that is being 'competed for' and 'allocated to'. Different from other MPI -IS research papers, this is a more general impression of 'low-level computer vision' research topics as opposed to the often highly specific contexts of the other papers focusing on researching one element or key problem of computer vision tasks.
When it comes to this visualisation decision, I want to create - at least in part - this 3D 'architectural space' because such visualisation comes closer to a human understanding and I want to communicate the idea of a dataset. Importantly, at the same time visually in the film I feel the need to give the footage SPACE. Just like in a graphic layout the use of white space is very important to allow content to unfold it's meaning and impression. If I would create just a 2D code heavy computer sees the world 'flat' impression I wouldn't be embedding the footage in a way that supports it best and allows it to unfold it's impression.
This is my artistic, aesthetic feeling. Of course, I want to stay in line with the concept and show the machine perception as truthfully as well.
The more research I do I realise it might not be absolutely necessary to show the dataset as an intact own entity existing in a separate space from the process. Again I think this is the most 'human' way of understanding it. However, I could just show the data inside the processing process. This process would of course become most clear for one data input at a time and then each video input would go through the same processing. Depending on how I create the filter representations and how often I could re-use elements to repeatedly show this process this would be a good avenue or not because it would mean producing more image and animation when I can also show the same processing put with less image material in a different way-
A video Dataset
It makes sense but is initially surprising that the department develops datasets and these are also scientifically published.
This kind of gives a feeling of re-legitimisation of my speculative dataset contribution. It is also kind of nice to read again and again that such novel datasets are missing, this also gives a sense that developing such datasets could be relevant.
source:https://ps.is.mpg.de/publications/butler-eccv-2012
+ I also just think that a 3D model moment in an art-film is really sexy. And I want to create such effect.
Although this kind fo goes in the right direction it isn't en detail what I am looking for.
source:https://ps.is.mpg.de/projects/scene-understanding
When looking at the datasets on github, the datasets are called like this:
source:https://github.com/anuragranj/cc
source:https://al.is.mpg.de/publications/eppe2022
This is a dataset on nature's species to tell scientist something from the data.
So does this apply to ALL NEURAL NETS WHENEVER THEY ARE USED? Or just a tool applied to a CNN trained for image recognition?
source:https://www.youtube.com/watch?v=yOyaJXpAYZQ
This video basically just compares the same equations in different languages
from C to machine language and shows how there are multiple mathematical ways to 'say' the same thing.
Thoughts and remarks from conversation with Armin and Hemal
Hemal: There are websites for visualisation of neural network layers processing your data which you can use to extract filter visualisations of each layer.
The overall theme is to put these topics in context.
+ You can even put the spin on it that when we see how the ANN is processing the data that maybe this is how animals are doing it as well. (Because both topics are somewhat black boxes to both scientist in both respective fields. We just don't really know so there is legitimate room for interpretation and being abstract.
This idea of using ANNS to give insight into animal perception is mirrored in the actual practice (of Armin's lab) using ANNs to make predictions on animal behaviour. ( Paper: ANNs to predict animal behaviour)
Also talked about how there is the parallel of howe we don't understand both human and non-human animals processing and the machines. In this way both 'representations' meet in the middle.
Armin: spoke about flexible neural net structures that are being developed that start out with a bit of room i.e. their model architecture is not fully defined and through running them they build their structure flexibly?
+ I should definitely add the document showing the presentation style to the proposal because this shows how all the research being done at CASCB is in a way also coming together for my installation. By creating an immersive screen we let the human be the 'test-viewing- specimen' and in a type of VE/VR give a similar sense to the type of VR world shown to specimens in the lab. This plays with the question scientist like Armin ask themselves when working with their specimens ' how do they see the world?'
Remark on reference images sent:
They show also what happens in the brain:
- Images on the Retina (filtering on several levels in the brain)
- Some form of abstract processing
- Distant structures in the brain
> 'Abstract is great' + there was a strong resonance with the Masaki Fusujaki image that Armin even argued was like the computers processing
Collab?
These are mainstream model on google Collab
> jpeg sequence on folder on my google drive
> cell inside Google Collab of each Network
> each step is in individual cells
> add code to get image print out
Have the result of each network and bring them together
DispNet > see the build process steps
first step - break down video to images > break rate for frames
Data-visualisation as an industry
There is a whole industry around how to visualise data and make it understandable for humans. This is mostly characterised by graphs and charts but should really drive home for me that data visualisation is a form of 'design for humans'
source:https://www.qlik.com/us/lp/sem/10-ways-to-take-your-data-visualizations-to-the-next-level?
Juro just showed me this video to give an understanding of computer video processing and that playback works through movement data that defines the movement from one frame to the next and not constant full frames because this would be unnecessarily computationally heavy.
Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation
'Unsupervised learning' : Unsupervised learning is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, which is an important mode of learning in people, the machine is forced to build a compact internal representation of its world and then generate imaginative content from it.
<> Ergo a more 'natural' form of learning.
The use of the KITTI dataset gives me an idea of how datasets are used by this framework and shows a 'DIRECTORY STRUCTURE' , which is something to adopt into my visualisation.
Is even appears that the dataset itself is compiled of multiple categories:
(1) stereo scene slow (2) multi-view extension (3) calibration files
Moreover, apparently the individual networks use specialised networks to run. (However, they are pre-trained so I wouldn't need to include their training in my visualisation.)
*Edit: Upon further research it starts to become more clear that
PoseNet: used for the pose/position of human bodies might not be directly applicable
(The model was trained using full-size human images(from eyes to ankles) and therefore the model works well when the user provides full-size human input.)
MaskNet: works with 3D point Cloud data which my dataset does not include.
It's interesting how such specialised Networks are used to try to answer such general 'vision' problems.
I believe Optical Flow is here used to attain structure from motion.
Is the numpy array the txt. file at the end?
source:https://ps.is.mpg.de/publications/adversarial-collaboration
Personal Note: Again and again I am overwhelmed by how complex the Networks are. Perhaps I can pay tribute to that by just making sure to not oversimplify it.
Goals of the framework:
- single view depth prediction
- camera motion estimation
- optical flow
- motion segmentation (segmentation of a video into the static scene and moving regions)
This is an interesting approach/ aim because it looks as vision as a more unified action, hereby coming closer to 'natural vision'.
Because this framework connects individual neural networks developed for a specialised subset of vision, the framework comes closer to a 'natural form ' of vision and is as such exactly right for my project.
Key features of the joint model:
- unlabelled data (unsupervised learning) (File name only, no additional annotation)
- coupled networks that can partition the dataset and use only the relevant data to each network respectively
- a 'generic framework' in which networks (can be different kinds than suggested in the paper) learn to collaborate and compete
- specific paper scenario: a three player game consisting of two players competing for a resource that is regulated by a third player, the moderator.
- resources are training data = These two players (R and F) compete for training data by reasoning about static-scene and moving-region pixels in an image sequence.
- this is moderated by a (pre-trained) motion segmentation network, that segments the static scene and moving regions, and distributes training data to the players.
- This training of the moderator happens in the 'collaborative phase of R and F'.
- Network for Depth (D)
- Network for Camera motion (C)
- Network for Optical flow (F)
- Moderator Network for motion segmentation (M)
- first player R= (DC) reasons about static regions
- second player F Optical Flow Network that reasons about moving regions
- M the Moderator is a motion segmentation network
- the moderator selects R or F respectively on either static (R) or moving (F) pixels in a region = competition is happening on a pixel-region basis
- during the training of the moderator the competitors form a consensus that is used as a loss(value tor train on) for the moderator
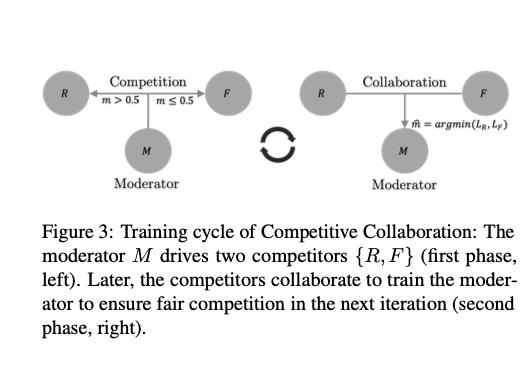
A combination of these two graphical visualisations give a sense of the frameworks architecture.
Executing visuals
source: https://www.youtube.com/watch?v=-MCGkpqQtQ0
GitHub: https://github.com/sedthh/pyxelate
Installation tutorial: https://www.youtube.com/watch?v=xWDe526RJcQ&t=0s
https://docs.opencv.org/3.4/d4/dee/tutorial_optical_flow.html
https://github.com/ml4a/ml4a-ofx/tree/master/apps/ConvnetViewer
Stage 0: Image Sequence
Stage 1: RGB Pixel values (- 1 x R 1x G 1x B ?)
Stage: Conversion to Greyscale?
Stage : Individual 'Neurons'/Nodes of a CONVOLUTIONAL network layer
Stage: Final Layer shows a compressed version of prior Convolutional Network layers
Stage: Motion Boundaries (Option but not necessary if ConvnetViewer)
Stage: Disparity Map
Stage: Disparity change Map
Stage: Basis flow fields of optical flow
(Stage: Optical Flow (with lines))
Images taken from Freiburg University Project providing Datasets of 'ground Truth' for different maps : https://lmb.informatik.uni-freiburg.de/resources/datasets/SceneFlowDatasets.en.html (which can be used to train models >I now need to find the models they used to create these maps.) ( main page: https://lmb.informatik.uni-freiburg.de/Publications/2016/MIFDB16/)
Stage 0: Image Sequence
Stage 1: via Pyxelate + RGB values manually?
> get values via Python:
Stage: Conversion to Greyscale?
Stage: ConvnetViewer
Stage: Final Layer shows a compressed version of prior Convolutional Network layers
Stage: Motion Boundaries (Option but not necessary if ConvnetViewer)
Stage: Disparity Map with DispNet?
Stage: Disparity change Map with DispNet?
Stage: Basis flow fields of optical flow (attained through complex process with GPUFlow)
(Stage: Optical Flow (with lines))
https://www.codementor.io/
https://github.com/rkripa/DispNet
My Data stages:
(1) Input image
(2) RGB image
(3) Disparity map
(4) Disparity change map
(5) (Motion boundaries)
(Optical Flow map (with lines))
(6) Edge Detection for single nodes
(7) Broken down abstracted flow fields for optical flow
There seem to be multiple iterations - feature maps / ‘activations’ - to one and the same image? I think they are neurons of one layer of the network - are ‘nodes’ feature detectors?
In this process the network is looking for pattern /’features’ that are lines or edges and THE DIFFERENT NODES OF THE NETWORK LAYER RESPOND TO DIFFERENT FEATURES.
The masks give the possibility to make it more artistic and again take away some of the it needs to be scientifically correct expectation by making it visually clear that it is an artistic work that get’s extreme in it’s own aesthetic of interpretation. So that the masks do come directly from the networks but there is also an artistic manipulation on top.
https://machinelearningmastery.com/how-to-visualize-filters-and-feature-maps-in-convolutional-neural-networks/
Article about the same principle using Keras: https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
& the updated version: https://keras.io/examples/vision/visualizing_what_convnets_learn/
Notes on mock-up film:
- because the grasshopper is not a 'full frame situation' it might be nice to show this one within the data-set structure
- to give some guidance and indication of what we are looking at there can be the file name at the bottom of the video plane, as well as the 'folder units' of the directory to pass through
- I think it's important to not ONLY have the image and videos in a void-space
- I want to find different ways to show the data-point, not always exactly the same sequence of events
- can there be some type of fluid transition from the lines in the 3D visualisation that the void-space fades to black and only the lines remain that take us into the 2D visualisation?
- does adding a pixelation/digital layer into the video-material confuse the purity if the 'animal perception' - it might get confusing 'what id the computer's processing and what is the animal's perception', better to keep the video-material 'clean' of any computerised effects and keep the computer processing as one identifiable section
Feedback from Leon:
- we (the viewer) should be more in it, not flying over the structure looking on from an outsiders/human perspective
- to do another mock-up on the expanded screen format to play with the possibilities in the space, like seeing another dataset off in the distance to the left or right, or seeing the ANN structure first distant to the left or right
- on the one hand I definitely agree that it can be more stream-lined and inside the computer, on the other the videos of the dataset already have a certain pace and we need to create a flow in the film. It shouldn't be like 'super fast'- 'super slow' extreme shifts
DURATION:
It is advisable to shorten the film, to keep an audience interested and keep it from feeling repetitive
Rachel Rose also limits her films to 8min. - 10 min. max
I can shorten the journey through the network, by making it faster it also comes closer to the fast-pace processing of the machine



conv1_grid
conv2_grid
conv16_grid
input image 224 x 224
Main aim:
TO SHOW COMPUTER VISION
AND ARTICIFIAL NEURAL NETWORK PROCESSING
What outputs exactly do I want:
- Squished square 224 x 224 input
- Single pixelated image (with RGB values) from one video frame/ single image png/jpeg
(ConvLayer Filters?)
- ConvLayer Feature Map animation in grid style of one video frame going through all ConvLayers of a Network > 25 fps > half a second per frame
- FlowNet optical flow map - mapped to greyscale
- (Disparity Map as output of ANN network (short animations))
- (Disparitychange Map (short animations))
(Compressed visualisation of all Convlayers in Network > as starting point for 2D Visualisation with Touchdesigner?) fc1 Dense layer
Selected animals:
Bee
(Field mouse)
Deer
Carp
My Data stages:
Input and preparation
- Input image
- Input image as 224 x 224 input
- Pixelated RGB image
Processing in architecture
- (Filters of ConvLayer)
- Convlayer Feature maps as grid animation moving through all Convlayers of Network
- (Broken down abstracted flow fields for optical flow)
Possible outputs from architecture
- Disparity map
- Disparity change map
- (Motion boundaries)
- (Optical Flow map (with lines))
Impression needs to be: computer is working through the video frame by frame
one frame goes through each CONVlayer
Next steps:
render out footage from animals without camera description tag
source: https://colab.research.google.com/github/ml4a/ml4a/blob/master/examples/models/FlowNetPytorch.ipynb
source FLOWnet2 on Colab: https://colab.research.google.com/github/Gauravv97/flownet2-Colab/blob/master/Flownet2_Colab.ipynb
GitHub for Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation: https://github.com/anuragranj/cc
I want/need a really clean pixelated look, not some pixel-art adaptation.
Until now using Excel with some coded Add-on looks like the best way to do that + even add in RGB colour values!
> I can do this on a microsoft
https://www.wiseowl.co.uk/blog/s2805/vba-pixellation.htm
Fred got the pixelate creator running for me on Colab but I think the style options are limited in the way that I will always get out a type of 'pixel-art' look.
I think it would be better to have the most 'matter-of-fact-style' I could achieve and not something so heavily - retro - stylised.
https://www.spreadsheetsmadeeasy.com/pixelate-images-in-excel-cells/
PIXEL ART for Google Sheets: https://www.labnol.org/software/turn-images-into-pixel-art/12978/
https://www.youtube.com/watch?v=hoHvxbKDO00
Interesting here is to use the screen in a more expansive 'collage-style' way.
00:40 - 02:04 für Data-stream close-up und für die Idee das man diesen 'Flash of white light' nutzen könnte auch um Übergänge zu gestalten
08:30 - data.scape Arbeit SOUND! Dieser Art 'Data-rush-welle' klingt sehr spannend
Basic structure -informed by what I know now - with a touch of the biological otherwise it's too far removed from the concept.
"Specifically, the models are comprised of small linear filters and the result of applying filters called activation maps, or more generally, feature maps.
Both filters and feature maps can be visualized."
"we develop machine learning methods in order to teach computers to recognise acoustic events. Our recogniser systems are trained with many hours of audio material. The audio signal is converted for this into so-called acoustic characteristics, which the computer then recognises as patterns. In our project group we have created a database with hundreds of different characteristics which are based on the results of fundamental research on hearing. We apply both statistical techniques and methods from the field of artificial intelligence for computer-based pattern recognition.
At the moment, the best recognition results are obtained with so-called artificial neural networks – that is to say algorithms which emulate the processing of signals in the human brain. We get close here to human recognition performance for recognition of non-speech acoustic events."
Humans have two ears – how many microphones does a computer need to “hear”?
At least two sound receivers are needed for spatial hearing. The human brain calculates the time offset and the difference in intensity between the sound waves arriving at the left and right ears in order to locate the source of a noise. We use several microphones, so-called microphone arrays, if spatial information is important for the recognition process. Depending on the application scenario, we use very tiny and also up to a hundred microphones. On the basis of these sound sources, a computer program, for example, can calculate the direction from which speaking is taking place and suppress noises from other directions. This method is called “beamforming”. Beamforming makes it possible to focus on a noise source and to zoom it up close.
> 'EVENT RECOGNITION'
> 'AUDITORY SCENE ANALYSIS'
- https://www.idmt.fraunhofer.de/en/Press_and_Media/insight_into_our_research/insight_computer_hearing.html
COMPUTER AUDITION / MACHINE LISTENING (HEARING)
"Inspired by models of human audition, CA deals with questions of representation, transduction, grouping, use of musical knowledge and general sound semantics for the purpose of performing intelligent operations on audio and music signals by the computer.
... deals with understanding of audio rather than processing....deals with general audio signals, such as natural sounds.."
> Auditory scene analysis: understanding and description of audio sources and events.
- https://en.wikipedia.org/wiki/Computer_audition
COMPUTER VISION - how to approach deconstructing and visualising this part?
Can we create an interpretation of this on the sound level when going into Data-processing by the network?
Deconstructing computer vision
Through: Generative ( e.g. GAN) approach
AND / or
Analytical (e.g. CNNs)
Generative Networks ( e.g. GAN) can show us how the network learns a STYLE on a surface level. What does the machine learn of the style it 'sees' - the network is built in such a way that it is prompted to answer this question by creating/generating something. In this way, it is an immediate answer fo the question posed 'What do you see'?
This approach feels more visually gratifying; more immediately 'artistic' and 'easier to understand' for an audience. ( It is however, also the most popular right now)
It might be possible to feed a GAN my imagery and see what comes out. The result would literally be a network that learned on my data and was asked what it sees in it. But it wouldn't be the deconstruction of that vision process? It would be the result. Granted however, with the animals it is similar; I'm not deconstructedly showing the vision process for each animal, MY PERSONAL PROCESS was that of deconstruction, but the outcome is the result of that put back together. So in that way it would be the same after all.
But it is not enough because it is not asking the question 'How do you see?'
The other approach would be the analytical. To look into the outputs of networks used for low-level vision tasks involved in scene detection ( now used in autonomous driving applications). This is an approach that is more so trying to build 'vision' analogous to human- vision from the ground up. Our also analogous to the animal, trying to deconstruct the vision process for a real-life scene and understand - similarly to the animal - how does this form of vision work? How does an ANN see a scene ?
This feels closer because the networks (BNN + ANN) are somehow confronted with the same challenge, the same TASK of scene understanding.
When creating the animal perspectives the question was to ask 'how can we come close to how we imagine animals see'?.
For machines it's not so straight forward because there are multiple possible applications for different kinds of 'seeing' / 'computer vision tasks'
The prior approach felt flawed because it wasn't asking : How can the networks organise - show- be integrated in every step of showing how they work? Instead of trying to show it from the outside with my human hand, I should be trying to show the networks and how they work at every step possible. By using the networks and showing how they work in a uncommented way I more follow the approach we took with the animals. The only reson I didn't want to do this is because I don't (yet) have the skills or people to execute it
- Inputs are extremely specific: specific format, homogenous
- there are several different forms of application, there is not the one and they are all task-based
- it is a streamlined process
- multiple computation steps
- the task-based/problem-solving nature of ANNs
What are the characteristics that make up Computer vision that should come across?
The question then for me arises whether it be possible to combine the generative and the analytical in the portrait of one network process. Doe GANS use convolutional layers?
These DCGANS definitely do BUT SO DOES REGULAR STYLEGAN architecture:
https://towardsdatascience.com/gans-part2-dcgans-deep-convolution-gans-for-generating-images-c5d3c7c3510e
https://neptune.ai/blog/6-gan-architectures
Should I visualisation of the sound take place?
Briefly thought about using T_SNE to organise my data but that doesn't make sense since it is 'just' an algorithm used to sort high dimensional data into a different visualisation from; it actually has very little to do with how computer vision works.. it is instead an ADDITIONAL. visualisation tool to help analysts understand how the model 'sees' the features.
But it is interesting as it introduces the idea of an algorithm 'looking at' the data and the concept of flexible visualisation.
The question would remain - even if I could get this to run with much effort, how would I show it in a visually strong way? how could I integrate these results in the video? Because I can't capture the movement of the sorting of the graph by applying it - I just end up having dots sorted and would have to 'copy' this in a high-quality image way..

This means:
1) * the representation of the dataset in void-space belongs to the chapter that establishes the dataset of 'animal intelligence'
* this needs time to be understood, what are we looking at, and give the time to dive into the multiple perspectives * sound and hearing - multiple perspectives
- in the edit this can be done by having the flashing image sequence of the dataset cut just before switching into the 3D void-space visualisation
2) * this part consists of showing: HOW an ANN processes the image (and sound) information provided by the dataset
> the cleanest way would be to use a network: train it on my data and show how the network 'sees' this data
> the direct comparison could be achieved by using the same exact running order of the network but then showing it as the optical flow and convolutional layer outputs
and ultimately break this down into machine-binarly-language-processing, as has been the plan
For these 'beings' /'entities' 'forms of intelligence' to 'face' one another they need to be separately established
Was wenn ma die Arbeit nochmal anders denken könnte, also im Editing den Verarbeitungsprozess spürbar macht;
wenn man mit einem intakten Datensatzt beginnt der über die Zeit immer heruntergebrochener, immer vereinfachter, immer machineller und dadurch immer mehr für den Menschen unnachvollziehbarer wird. Quasi dieses herunterbrechnen durch die machine in seine Bestandteile erlebbar macht. Quasi den Datenverarbeitungsprozess über den Verlauf des Filmes simuliert. Am Ende bleibt die Linie, das 'aktionspotential'
Dramaturgie/ story-arch
moving from multiple highly complex perspectives into the relentlessly task focused machine.
Wenn ich mit einer Gegenüberstellung arbeite, dann muss ich auch mit einer Gegenüberstellung arbeiten und nicht alles zusammen matschen. Wenn 'vis a vis' das core-concept ist, muss das auch im Edit spürbar werden.
* with the animals I am also not showing a look outside - it's just straight into the perspective
2) the ( audio + visual) processing of an artificial neural network (deconstructed and interpretation of computer vision process in low-level vision tasks)
Within this I can follow two paths:
1) a convolutional network in low-level vision tasks that disassembles an image akin in some ways to what an eye does
2) to show how DIFFERENTLY artificial networks process images
> using a GAN trained on my data to show how a neural network seeeeees my data?!
It's not about using GANs or any neural network to execute on the speculative narrative and give 'truth' to my dataset, rather it is about using the data I created to give an insight into how computer vision works - to use my data not in a continuation of the narrative but as in-put data for an artistic research on computer vision.
The 'cleanest' way to give an insight into how the network sees my data is to actually give it to a network TRAINED on MY DATA and look at the outcome from that process.
Another indicator that it is in a fact a vis-vis positioning of biological and artificial, is that they are being produced largely separately from one another and then brought together for the film's narrative.
data archive - to - image processing
The crux of the project is to use the same approach both towards biological /animal and artificial and make visible the implicit similarities and differences between the two.
Through this positioning of both 'entities' face to face the question of what is deemed / termed 'intelligent' is implicitly asked. The answer lies in the comparison and the viewer's own associations between both positions.
What if instead of trying to SHOW the networks from the outside I use networks to look at the data and show how THEY SEE, HOW THEY PERCEIVE.
Other than the animals here I actually can 'let the networks speak for themselves'
The issue with training a network on the image quality scale I would need is extremely heavy and takes extremely long
The shifting nature of visualisation can be communicated by showing the data not in a fixed form but multiple forms..
2) the question once again is: WHICH ANNS ARE APPLICABLE TO MY USE CASE AND DATASET?
> video dataset
> about vision : ANNS involved in solving low-level vision tasks using video sequences: like MaskNet, FlowNet, DispNet used in Competitive Collaboration Framework
> Generative Adversarial Networks << why did I not decide to go with these from the star? because I thought they are not ANNs in the 'true' sense - they are a different form of 'machine learning' + I felt that the data I could provide is not appropriate to teaching a GAN because it is not a huge variety but as a video there are other aspects of more complex 'vision' that could be dealt with here. STYLEGAN is more about 'learning' the style of an image rather than engaging in aspects of 'low-level vision' from a fundamental perspective
However: "GANs require a lot of data because they use neural networks to generate new images and audio."
GANs are the form of network structure used to computer generate imagery - in this way they DO GIVE A SEEABLE SENSE OF HOW THE NETWORK 'SEES' THE PROVIDED DATA
AND WHAT DEFINES COMPUTER VISION - WHAT ARE THE CHARACTERISTICS
- lives from repetition not from 'abstraction' - 'learning' is not abstraction through meaning but fulfilling a task correctly through REPETITION
- datasets are LARGE with similarities + variety ( need for grouping while not over-fitting)
- datasets need to be homogenous in dimensions ( e.g. SQUARE 256x256; 1020 x 1020 , colour space ) > need to be STANDARDISED
- the 'bottleneck' through which the data needs to fit is very small or the network code will through an error
- problem-solving; task- based (task and yes/no feedback)
I am taking the creative decision to NOT include an analysis of computer audition into the work because this is extending beyond my capacity for this work and with the concept based argumentation that networks always only look at ONE aspect < this is another form of information reduction < possibly then the sound void should be emphasised! < like once it goes into the Image Data-processing we loose the sound and only have a void-like sound
The moment of THE LOSS OF AUDIO should be emphasised with a vacuum-ish sound that pulls it away - afterwards a void that slowly builds up to be more atmospheric
Boreal Kiss Pt. 1 - Tim Hecker , has some fitting sounds
To underline the idea that there is a multitude of networks bUT ESPECIALLY THAT THEIR REPRESENTATION IS A FORM OF VISUALISATION I could show diagrams of different networks ( that should be all used for computer vision related tasks) in a similarly fast collage style to how I show the dataset
This reminds me of how I will row the image sequences
Instead of struggling to show ONE perfect Network; I can show that it is a matter of visualisation by showing outlines for several?
directly inspired by https://philippschmitt.com/work/blueprints-for-intelligence
Does it make sense to give it the whole dataset - which is a wild mix of different perspectives? leading into a mosh-up situation? or would it make sense to train it on each animals perspective < hereby not having enough variety in the data and leading to overfitting where the network doesn't know how to generalise form the data I provide it..?
> the question is, is it 'worth it' to train a GAN on a very diverse dataset that has little variety of the same thing?
> It seems to me like with GANs the INSIGHT ON HOW THERE 'VISION' WORKS IS RATHER THE INSIGHT ON HOW RESTRICTIVE THE DATASET HAS TO BE
> so if I don't have the right kind of dataset fro GANs maybe it IS interesting to show how unflexible computer vision is by showing the reaction to my dataset..
THE AI PART IS ABOUT COMPUTER VISION AND (the topic of) VISUALISATION
training the GAN with Video
it would THEN make sense to run it on individual perspectives ( for cleaner results?) or mix them together
Showing different concepts of cognition ( as visualised and documented from a human perspective)
This project by Phillip Smith https://humans-of.ai/?img=1#5718,2284 , that emphasise the people /photographers who contribute to datasets again makes it more clear to me that because my dataset is one of video, it's about scene understanding and analysing the image from a visual cortex perceptive. Not at all from the classical image recognition perspective.
I feel that I am coming to the painful realisation that I need to run and train a network myself on our workstation starting next year.
What I could run would be a GAN for a look at generative
approach of a Network used for image generation
or analytical look at low-level vision tasks.
But I honestly don't feel the point of trying a DispNet or FlowNet because I don't have sufficient data for it..
Maybe it doesn't have to be a question of doing everything form the ground up but 'how does the embedding work'?
I basically just want to ask the simple question: what does an ANN SEE when looking at my data?
EDITING: Vis a Vis
- The positions of the dataset of animal perception vis a vis the processing of a neural network will become more clear if the positions are at first not mixed but established on their own:
1) the dataset ( deconstruction and interpretation of the vision and hearing of animals ( biological neural networks))
face to face with
2) the ( audio + visual) processing of an artificial neural network (deconstructed and interpretation of computer vision process in low-level vision tasks)
<< both forms of 'vision' / 'perception' and the implicit difference of 'intelligence' are dealt with in similar way and become counterparts for one another
the act of processing the data becomes the binding/connecting element but carries less importance in the editing of the film and construction of the plot
*here: it is not important to show the network from the outside but to tell deep dive into neural network processing - not explained but experienced > be inside the workings of the network
I think the first part of deconstructing the vision process is
to show the variable/ unfixed views on the data
Nicht von außen ein rein Menschengemachtes Gebilde
Kamerafahrt ist fürs menschliche Auge aufbereitet und genau das wollen wir ja eig. nicht machen. Der Datensatz ist für die Machine und wird von der Machine gesehen deswegen macht es Sinn es da näher dran zukommen und nicht für den Menschen aufbereitet. Es muss sich anfühlen wie als käme es aus ner Machine.
Nicht vom Menschen oder für den Menschen aufbereitet.
Wie muss der Datensatz für die aussehen. Nicht breit tretten der Thematik das die Netzwerke ein extrem imitierendes Bottleneck haben?
Re-evaluation Visualisation approach
A. Dataset
B. ANN
1. ConvLayer visualisation
2. Kernel visualisation
3. Fully connected ('activation') layer?
(3. Data organisation with T-Sne < not needed and over complicating again?)
Dataset: 2D Video Footage
Dataset with TD: Grid like fold-outs of data-points?
TD: Kernels / Filters as Animation < additional research on what Kernels are and what they can look like
ANNs: ConvLayer Visualisation of actual amount of Feature Maps < how I lay this out and in which sequences I use the feature maps can create visual interest while staying close to the vest conceptually
Cut: NO optical Flow Output, NO Network Visualisation from the outside
Instead of having all these multiple different forms of visualisation it does make sense to keep the dataset visualisation and the ANN visualisation similar to one another in style:
e.g.
- working in 2D
- grid-like fold-outs extending over the screen
Could it even be considered 'wrong' to have the dataset in a three-dimensional representation because this space is NOT 3Dimensional to the network? Only once the data goes into the networks it does go into an n-dimensional space, within which the data could have a positioning in multiple dimensions. However, this is definitely not the case from the onset, therefore in the narrative of space it does make more sense to stay flat in the representation of the dataset?
THESIS WRITING:
The reasoning/ explanation that because this is such a 'general model' that performs well and has a simple structure is a very good approach to explain why I will use it to visualise how convolutional feature detection of an image recognition network works.
https://www.kaggle.com/code/loaiabdalslam/vgg16-layers-visualization-tutorial/notebook
The 'learned filters' are the 'weights' also called 'Kernels'
The are the 'learnings' with which the pre-trained network looks at the new data.
Don't have to fake it; could get 'real output < tHere we only see the first 6 of 64 < could I get more? < yes baby :)
ConvLayers = What is being 'seen'
Kernels = what is being 'looked' with
In this way I AM de-constructing the computer vision process (without over emphasising the network use-case (e.g. prior low-level vision idea) or outputs (e.g. modified optical flow maps), but only the 'internal workings' instead)
I got lost in the complexity of the subject and thinking I need to represent this complexity I was encountering fully. Turns out it's much more valuable and in support of my narrative if I focus on a simplified visualisation of the mathematical/operating process of the network.
(The simplicity of the machine visualisation also complements the aimed for complexity of the animal footage. Only by making the visualisation of the AI simplified can the depth /complexity of the animal footage become visible. / Erst indem die Visualisierung der KI absichtlich reduziert dargestellt wird, kann die Komplexität und Tiefe der Tier-sicht-aufnahmen zur Geltung kommen. Diese Darstellungspanne von möglichst mehrschichtig (möglichst viele Informationen die in die Videobilder komprimiert werden) zu vereinfacht/flach/schlicht unterstützt das narrativ der informations Reduktion & Verlust.
The thesis film might have been extended / expanded upon by fully using the dataset to train a convolutional neural network:
Then the project would have further included,
> preparing the images as training data
> training a convolutional network on it
The question is however, what is the actual value of training a network only briefly on my dataset which is built so differently. IT IS MORE IN SUPPORT OF THE CONCEPT TO CREATE A CONTRAST AND SHOW THE LIMITATIONS OF HOW IMAGENET TRAINED NETWORK CAN'T RECOGNISE ANYTHING OUTSIDE OF IT'S NORMS.
Es wäre auch keien schlüssige aussage wenn ich ein netzwerk auf meinen Daten trainieren würde aber viel zu wenig & zu kurz , der outcome wäre eig. nichts sagend - ich hätte es nur gemacht.
Wenn ich meine Daten einem pre-trained Network gebe dann setzet ci diese (meine) Daten in eine unmittelbaren dialogue mit pre-trained knowledege / Daten.
https://cs.stanford.edu/people/karpathy/tsnejs/csvdemo.html
The take-away here can be that data is always numbers for the model
> matrix multiplication
'38.195070, -84.878694
30.443345, -91.186994
44.318036, -69.776218
38.976700, -76.489934
42.358635, -71.056699'
Inspiration works by Phillip Smith
" through the sober eyes of neural networks, vectors and pixels "
https://philippschmitt.com/archive/computed-curation-web/
This would ONLY MAKE SENSE IN MY WORK IF THE NETWORK WAS TRAINED ON MY DATA and then synthetically activated to show in each feature map what it has learned through training . It is more a way of fooling or hacking the network (Although this synthetic activation is somewhat more artistic , the feature maps are closer to what is 'actually' happening in the network just with the added step of outputting/plotting the output
What can be seen more beautifully in these maps is how they grow and evolve to higher level features, this same impression is inverse when looking at the feature maps
We have VGG16 on Colab now
Other option could have been using ResNet with Pytorch :
https://debuggercafe.com/visualizing-filters-and-feature-maps-in-convolutional-neural-networks-using-pytorch/
https://debuggercafe.com/visualizing-filters-and-feature-maps-in-convolutional-neural-networks-using-pytorch/




"The main goal of t-SNE is to project multi-dimensional points to 2- or 3-dimensional plots so that if two points were close in the initial high-dimensional space, they stay close in the resulting projection. If the points were far from each other, they should stay far in the target low-dimensional space too."
Although the basic idea of 'visualising the data' in a new way through an algorithm sounds interesting - I don't need my data plotted through an additional visualisation tool.
I instead focus on how the ANN 'sees' the data - this would be the addition of another algorithm that moves the data from high-dimensional representation to something easier to read.
When artistically it would actually be more interesting to see the complexity
"We will apply t-SNE to the features extracted by ResNet101 network."
T-SNE is used on the data after it has been processed by a network like Res-Net , this is how T-SNE can reveal something about the data and model
T-SNE 'only' plots the labels / results outputs in space
But for me the further interpretation of the data is not so important because it is about charting the differences in 'seeing' and 'being' in general
I don't want to use the T_SNe algorithm but I will use this clustering of data or pixels as inspiration/influence in my editing style
https://learnopencv.com/t-sne-for-feature-visualization/
https://learnopencv.com/t-sne-t-distributed-stochastic-neighbor-embedding-explained/
Add classification layer to out VGG model?!? - https://www.oreilly.com/library/view/practical-convolutional-neural/9781788392303/f421eabc-c512-4701-89a7-f6c757669ee7.xhtml
Inside of an ANN "Firing a neuron" article
"When an input is leaded to a neuron, an output will be built after processing step. This output will be generated after the firing of the neuron only if the output is strong enough or have a considerable weight. In the neurons in the human brain there are several normal, weak processing are happening which are useless. Generating an output by a neuron because of obtaining an input by it is called as the firing process of the neuron."
Important VGG16 - related articles:
https://www.kaggle.com/code/loaiabdalslam/vgg16-layers-visualization-tutorial/notebook !!! < code used to visualise the kernels hosted in Colab < Kernels explained well
https://machinelearningmastery.com/how-to-visualize-filters-and-feature-maps-in-convolutional-neural-networks/ < prime article Fred mainly oriented on for putting VGG16 on Colab < bird example
https://towardsdatascience.com/convolutional-neural-network-feature-map-and-filter-visualization-f75012a5a49c
https://neptune.ai/blog/understanding-vectors-from-a-machine-learning-perspective < understanding vector space
Personal notes
http://www.subsubroutine.com/sub-subroutine/2016/9/30/cats-and-dogs-and-convolutional-neural-networks < early article in my research on CNNs
https://indiantechwarrior.com/tensorflow-pooling-layers-in-convolutional-neural-network/ < explanation on Max pooling
https://www.kaggle.com/code/anktplwl91/visualizing-what-your-convnet-learns < different forms of Filters/Kernel styles + activation map for input image with Inception V3 model
https://www.researchgate.net/figure/sualizing-the-learned-filters-in-the-custom-trained-VGG-16-model-a-block1-conv1-b_fig4_326557171< visualising filters to understanding the learned filters of trained VGG16 model
https://www.mygreatlearning.com/blog/image-recognition/#:~:text=into%20various%20categories.-,How%20does%20Image%20recognition%20work%3F,how%20to%20recognize%20similar%20images. < original orientation article
https://ai.stackexchange.com/questions/17004/does-each-filter-in-each-convolution-layer-create-a-new-image < understanding network operations < forum conversation
https://marutitech.com/working-image-recognition/ < valuable over view of image recognition
https://towardsdatascience.com/extract-features-visualize-filters-and-feature-maps-in-vgg16-and-vgg19-cnn-models-d2da6333edd0 < overview of VGG16 specifically
https://towardsdatascience.com/applied-deep-learning-part-4-convolutional-neural-networks-584bc134c1e2 < run down CNNs generally
Trying to understand vectors space :